TripoとZillizで検索可能なAI 3Dアセットライブラリを構築する
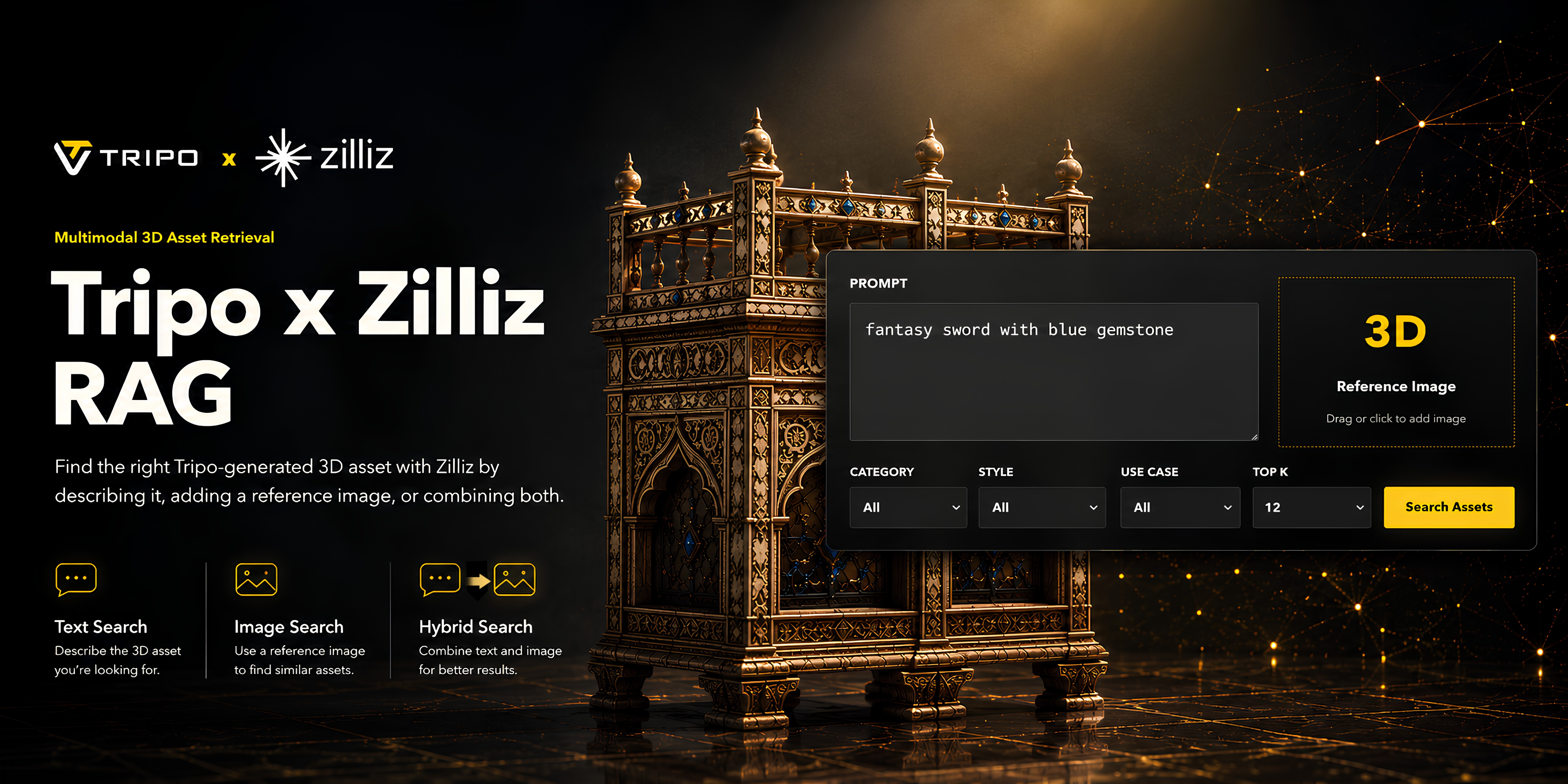
AIによる3D生成(AI 3D generation)により、チームが大規模に3Dアセットを作成することが劇的に容易になっています。Tripoを使用すると、クリエイターはテキストプロンプトや参照画像から高品質な3Dモデルを生成できるため、ゲーム開発、EC向けのビジュアライゼーション、マーケティング制作、コンセプトデザイン、社内のクリエイティブワークフローなどに役立ちます。
しかし、生成されるアセットの数が増えるにつれて、新たな課題が生じます。
「目的の3Dアセットをいかに素早く見つけるか?」という課題です。
チームが所有するモデルが数個だけであれば、フォルダ名による分類や手動でのブラウジングで十分かもしれません。しかし、生成されたアセットが数百、数千に達すると、従来のファイル管理手法は機能しなくなります。デザイナーが同様のアセットを繰り返し生成してしまったり、ゲーム開発チームが便利なキャラクターやプロップ(小道具)のバリエーションを見失ったり、マーケティングチームがアセットを使用する時間よりも探す時間に多くの時間を費やしてしまうことになりかねません。
そこで、検索可能なAI 3Dアセットライブラリが真価を発揮します。
このワークフローでは、Tripoが3Dアセットを生成し、Zilliz Cloudがマルチモーダルベクトルとメタデータの検索(リトリーバル)レイヤーとして機能します。Zilliz Cloudは各レンダリング画像を表すembeddings(埋め込みベクトル)を保存し、それらをカテゴリ、スタイル、色、オブジェクトタイプ、ユースケース、ソースファイルなどの有用なメタデータフィールドと関連付けます。その結果、ユーザーはテキストや参照画像、あるいはその両方を使って検索し、構造化されたメタデータとともに関連するTripo生成のレンダリング画像を取得できる、軽量なマルチモーダル検索システムが実現します。
ZillizはAIデータインフラ企業であり、このワークフローの基盤となるオープンソースのベクトルデータベースMilvusの開発元です。Milvusは、RAG、AIエージェント、マルチモーダル検索、レコメンデーションシステム、企業向けナレッジベース、セマンティック検索、コンテンツの重複排除など、本番環境のAIユースケース向けに構築されています。また、Linux Foundation AI & Dataの卒業プロジェクトであり、GitHubで44,000以上のスターを獲得し、1億回以上のDockerプル数を誇るなど、非構造化データのベクトル埋め込みを保存・検索するための信頼性の高い基盤をチームに提供します。
これはTripoユーザーにとって重要な意味を持ちます。なぜなら、各3Dアセットは単なる1つのファイルにとどまらないからです。各モデルは、レンダリングプレビュー、入力参照画像、キャプション、タグ、カテゴリ、色、ユースケース、プロジェクトID、URLなどと紐付けることができます。Zilliz Cloudはこれらのシグナルを統合して検索可能にするため、増え続けるAI生成モデルのライブラリが、単なる使い捨てのアウトプットのフォルダではなく、再利用可能な本番用のアセットシステムへと生まれ変わります。
なぜ検索可能な3Dアセットライブラリを構築するのか
AI 3Dツールは制作スピードの向上に優れています。今や1人のクリエイターが、キャラクターのコンセプト、プロダクトのモックアップ、プロップ、背景要素、スタイライズされたアセットなどを極めて短時間で複数生成できます。
しかし、スピードは量を生み出します。そして、量は管理の問題を引き起こします。
検索可能な3Dアセットライブラリは、いくつかの一般的な課題を解決するのに役立ちます:
- チームは、重複するアセットを新しく生成する代わりに、既存のアセットを素早く見つけることができます。
- デザイナーは、コンセプト、スタイル、色、オブジェクトタイプ、またはユースケースから検索できます。
- デベロッパーは、プロジェクト間で3Dアセットをより効率的に再利用できます。
- クリエイティブチームは、承認済みの再利用可能なビジュアル素材の社内ライブラリを構築できます。
- ECやマーケティングチームは、製品に似た3Dアセットをカテゴリやスタイル別に整理できます。
AIで生成された3Dファイルを単発のアウトプットとして扱うのではなく、このワークフローによって再利用可能なアセットシステムへと変換します。
なぜZilliz Cloudがマルチモーダル3Dアセット検索に適しているのか
Zilliz Cloudは、Milvusの作成者によって構築された、フルマネージドなVector Lakebaseプラットフォームです。その中核をなすのは、1,000億規模のデータに対して高スループットかつ低レイテンシのベクトル検索を実現する本番グレードのベクトルデータベースです。そのコアの周囲で、Zilliz Cloudはマルチモーダルデータレイクのオープン性、拡張性、および経済性によってベクトル検索を拡張し、本番環境のAI向けに非構造化データを検索、分析、ガバナンスするための単一のプラットフォームをチームに提供します。
3Dアセットライブラリのデータは本質的にマルチモーダルであるため、Zilliz Cloudはこの用途に最適です。検索可能な3Dカタログでは、レンダリング画像、参照画像、テキストキャプション、生成されたメタデータ、チームの所有権フィールド、およびプロジェクト固有のタグを同時に扱う必要があります。Zilliz Cloudは、ベクトル検索とメタデータ取得を通じてこれらのシグナルを連携させるため、ユーザーは意味、視覚的類似性、構造化されたフィルター、またはそれら3つの組み合わせからアセットを検索できます。
Zillizはこのプロダクトの進化について、From Vector Database to Vector Lakebase や Why We Built Vector Lakebase で説明しています。重要な考え方は、現代のAIシステムには近傍探索(nearest-neighbor search)以上のものが必要であるということです。また、リアルタイムでのサービング、反復的なディスカバリー、バッチ分析、そして急増する非構造化データセットに対するガバナンスのためのデータ基盤も求められます。これらのニーズはAI 3Dライブラリに直結しており、チームは今日の最適な結果を取得しつつ、時間の経過とともにカタログを改善し続けたいと考えています。
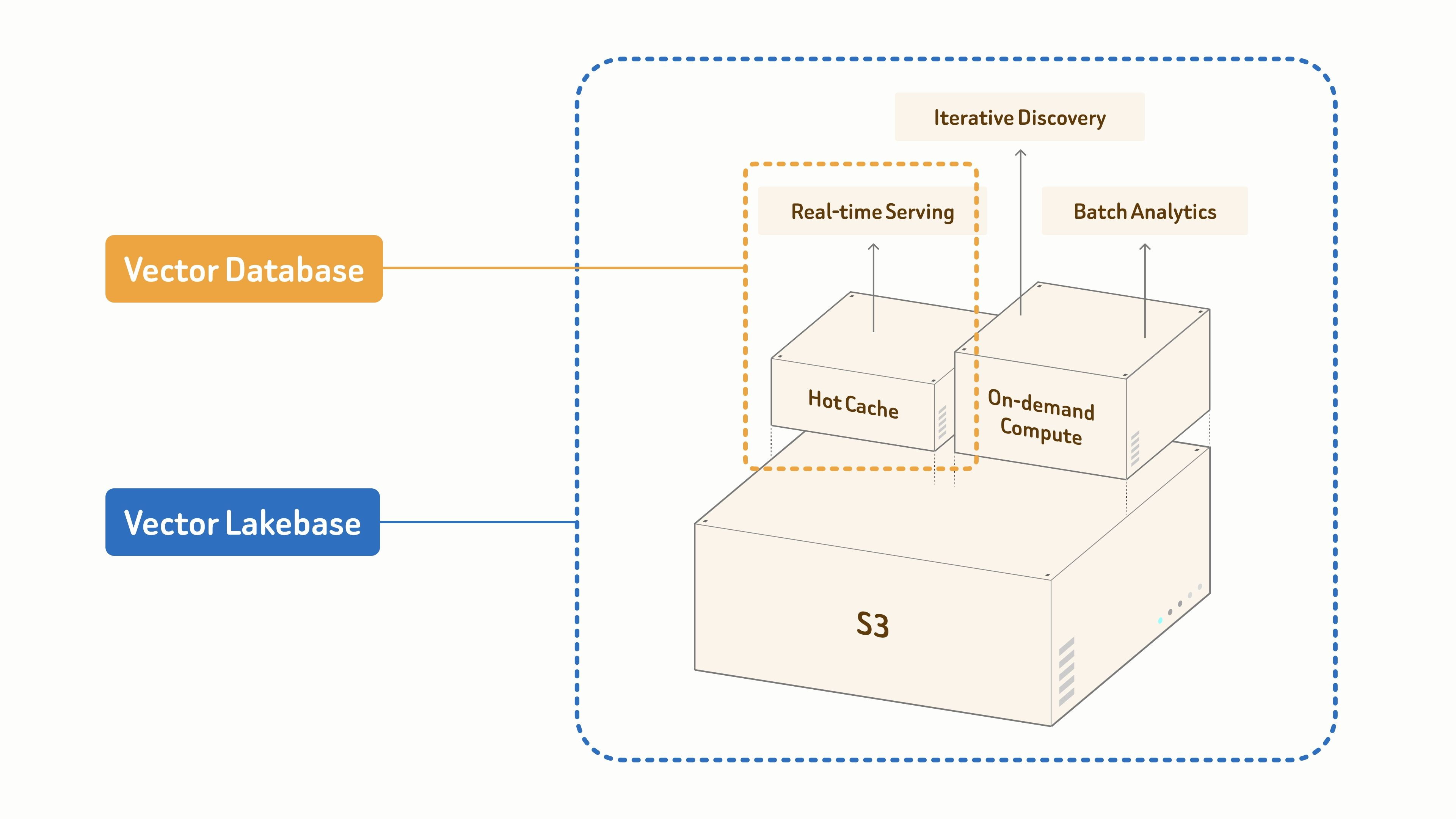
ワークフローの概要
このデモでは、以下の3種類のローカルデータを使用します:
- CSVファイル:カテゴリ、スタイル、オブジェクトタイプ、色、ユースケース、ファイル名、関連するプロジェクト情報など、各3Dアセットのメタデータを保存します。
- milvus_render_images/ フォルダ:Tripoで生成されたアセットのレンダリングされたプレビュー画像を保存します。これらのレンダリング画像が主な検索対象となります。
- milvus_input_images/ フォルダ:image-to-3D生成時に使用された参照画像を保存します。これらは主にメタデータやオプションのクエリ参照として使用されます。
簡単に言えば、この構成により、ユーザーは必要なものをテキストで説明したり、ビジュアル参照をアップロードしたり、あるいはその両方を組み合わせて、ライブラリから関連するアセットを見つけることができます。
前提条件
開始する前に、以下が準備されていることを確認してください:
- Zilliz Cloudアカウント:Zilliz Cloudは、Milvus의作成者によって構築されたフルマネージドなVector Lakebaseプラットフォームです。本番グレードのベクトルデータベースと、マルチモーダルデータに対応したレイクネイティブな基盤を組み合わせているため、ベクトルインフラを自ら運用することなく、埋め込みベクトルと構造化メタデータを保存できます。本ガイドを進めるには無料プランで十分です。Zilliz Cloudにサインアップし、無料のクラスターを作成して、そのURIとトークンを取得してください。
- 以下で使用するGeminiマルチモーダル埋め込みモデル用のOpenRouter APIキー。
- Python 3.10以降(Milvus Python SDKがインストールされていること:
pip install -U pymilvus)。初めて使用する場合は、PyMilvusインストールガイドを参照してください。 - Tripoで生成された3Dアセット一式:レンダリングプレビュー画像、および(オプションで)image-to-3D生成に使用した参照画像。
ステップ 1: Tripoで生成された3Dアセットデータの準備
最初のステップは、Tripoを通じて生成されたデータを準備することです。
各アセットには、少なくとも以下が含まれている必要があります:
- レンダリングプレビュー画像
- CSV内のメタデータ行
- オプションの入力/参照画像情報
- 利用可能な場合は、カテゴリ、スタイル、ユースケース、オブジェクト、色の各フィールド
例えば、あるアセットのメタデータは以下のようになります:
| フィールド | 例の値 |
|---|---|
| Category | Character |
| Style | Fantasy |
| Object Type | Female warrior |
| Color | Blue, Silver |
| Use Case | Game asset |
| File Name | warrior_female_01.webp |
このメタデータは重要です。なぜなら、ベクトル検索だけでは必ずしも十分ではないからです。実際のアセットライブラリでは、ユーザーはセマンティック検索とフィルターを組み合わせたいと考えることがよくあります。
例えば:
- 「game asset」ユースケースの中から「female character(女性キャラクター)」を探す。
- 「weapon」カテゴリの中から「fantasy sword with blue gemstone(青い宝石が付いたファンタジーソード)」を探す。
- realistic(リアル)、cartoon(カートゥーン)、sci-fi(SF)、low poly(ローポリ)など、特定のビジュアルスタイルのアセットを探す。
メタデータの構造が優れているほど、アセットライブラリの有用性は高まります。
埋め込み時の画像フォーマットの制約
保存効率を高めるため、レンダリング画像と入力参照画像は**.webp**形式で保存されています。
しかし、Geminiの埋め込みモデル(gemini-embedding-2-preview)が確実にサポートしているのはPNGおよびJPEGの入力のみです。WebP画像を使用すると、APIのバックエンドによっては埋め込みに失敗する場合があります。
そのため、埋め込みを生成する前に、画像をPNGまたはJPEGに変換する前処理ステップが必要となります。
ステップ 2: Zilliz Cloudコレクションの作成
Zilliz Cloudでは、コレクション内の各レコードが、Tripoで生成された1つの3Dアセットを表します。
ここでVector Lakebaseモデルが役立ちます。従来のベクトルデータベースはリアルタイムの類似性検索に優れています。Vector Lakebaseはその検索パスを維持しつつ、マルチモーダルデータ、バッチ分析、反復的なディスカバリー、およびガバナンスのための、共有されたレイクネイティブなデータ基盤を追加します。このデモでは軽量な方法で使用しますが、同じ構造でTripoアセットライブラリがはるかに大規模になっても対応できます。
コレクションは、構造化されたメタデータとマルチモーダルベクトルの両方を保存します。主要なベクトルフィールドは multimodal_vector です。このデモでは、ベクトルの次元数は3072で、類似性の指標としてCOSINEを使用します。
テキスト、画像、およびテキスト+画像のクエリはすべて同じベクトル空間に埋め込まれるため、システムは1つの統合されたベクトルフィールドを使用してすべてのアセットを検索できます。
以下は、簡略化されたスキーマ設定のコードです:
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
次に、ベクトルインデックスを作成します:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
スキーマとインデックスを定義した後、以下を実行します:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
コマンドの実行が完了すると、Zilliz Cloudコンソールでコレクションを確認できるようになります。
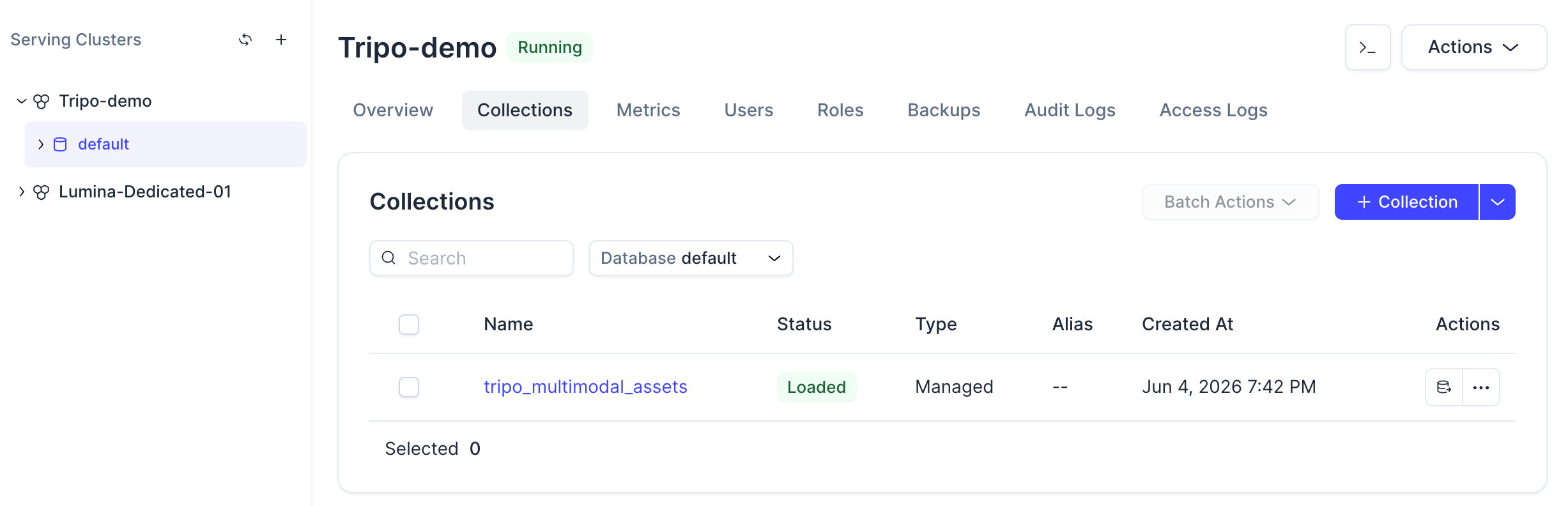
コレクションをクリックすると、そのステータス、スキーマ、ロードされたエンティティ、およびベクトルフィールドの設定も確認できます。
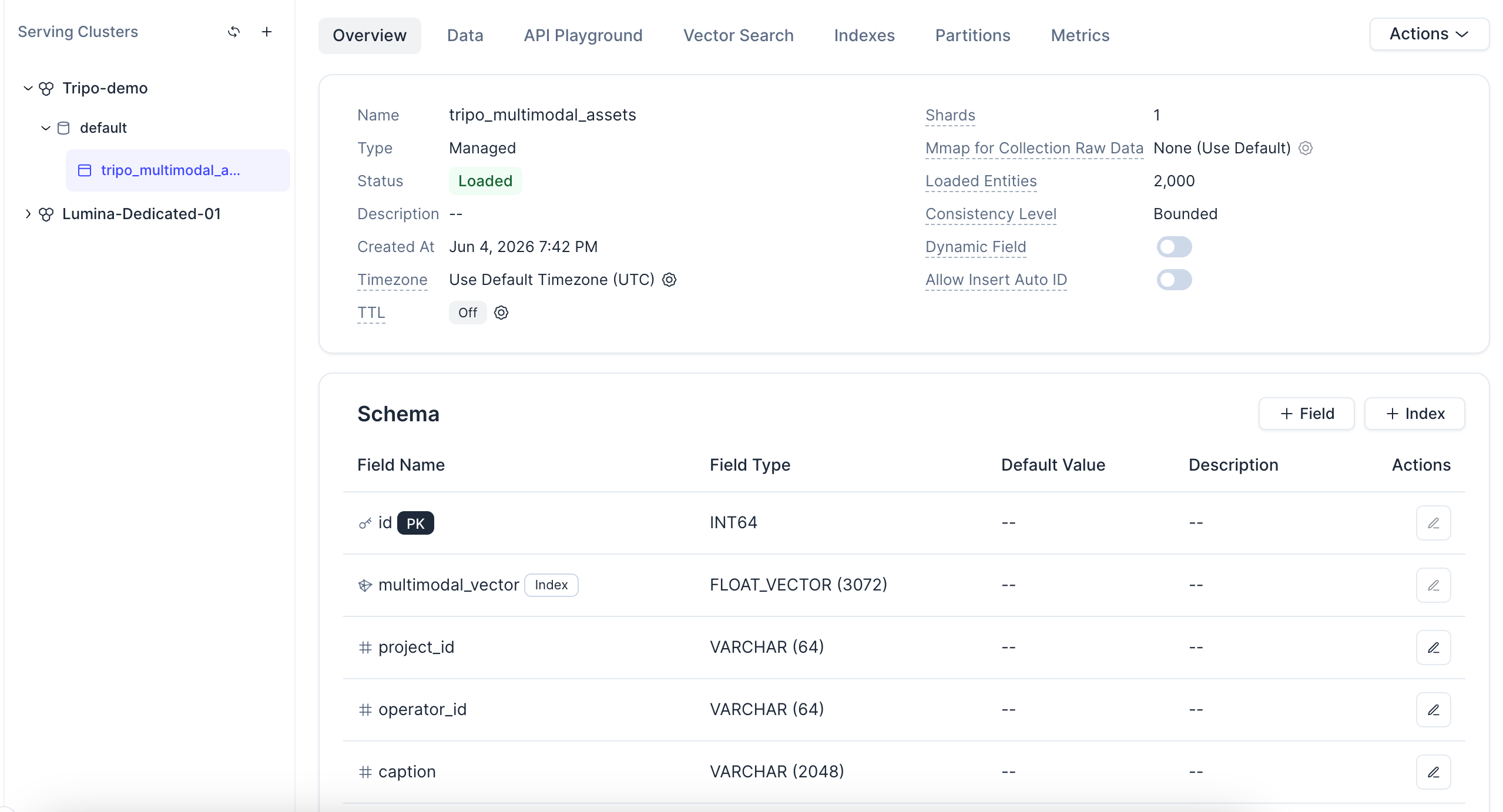
インデックスに関する注意点:このデモではAUTOINDEXを使用しています。これにより、Zilliz Cloudがデータに基づいて自動的にベクトルインデックスを選択およびチューニングするため、インデックスタイプやパラメータを手動で選択する必要はありません。COSINEメトリックタイプは、次のステップで生成されるL2正規化された埋め込みベクトルに対応しています。また、各レコードはマネージドコレクション内の1つのエンティティであるため、同じセットアップで、再アーキテクチャ設計を行うことなく、数百のアセットから数百万のアセットへとスケールさせることができます。
ステップ 3: レンダリング画像の埋め込みベクトルの生成
次に、Tripoのレンダリングプレビュー画像の埋め込みベクトル(embeddings)を生成します。
このワークフローでは、レンダリング画像をbase64のデータURLに変換し、埋め込みモデルに送信します。返されたベクトルは正規化され、COSINE類似性検索で使用できるようになります。
以下がそのコアロジックです:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
データセット全体の埋め込みキャッシュを構築するには、以下を実行します:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
埋め込みの生成には時間がかかり、APIの状況にも依存するため、キャッシュのステップは非常に有用です。データをインポートするたびに埋め込みを生成する代わりに、一度キャッシュを構築すれば、インポート処理中にそれを再利用できます。

埋め込み(embedding)キャッシュを生成した後、CSV の各行は 1 つの Zilliz Cloud エンティティに変換されます。
各エンティティには以下が含まれます:
- アセット ID
- プロジェクト ID
- オペレーター ID
- キャプション
- LLM によって生成されたメタデータ
- 生成モード
- レンダリング画像ファイル情報
- 入力画像ファイル情報
- マルチモーダルベクトル
以下は、エンティティ変換関数の簡略化されたバージョンです:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
次に、データセット全体をインポートします:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
インポートが完了したら、Zilliz Cloud コンソールを開き、Data タブを確認します。メタデータフィールドとベクトル情報を含む、インポートされたアセットレコードが表示されているはずです。
この時点で、Tripo で生成された 3D アセットは単なるローカルファイルではなくなりました。これらはベクトルデータベース内で検索可能なエンティティとなっています。
ステップ 5: 3D アセットライブラリの検索
検索システムは、以下の 3 つのクエリモードをサポートしています:
- テキスト検索 — 意味的な説明による検索
- 画像検索 — 視覚的な類似性による検索
- テキスト + 画像検索 — 両方を組み合わせてより精密に検索
3 つのクエリタイプはすべて、同じマルチモーダル埋め込みモデルを使用してベクトルに変換されます。その後、クエリベクトルは Zilliz Cloud 内の multimodal_vector フィールドに対して検索されます。
テキスト検索
テキスト検索は、ユーザーが欲しいものをすでに把握している場合に便利です。
クエリの例: "青と銀の鎧を着た女性キャラクター"
システムはテキストクエリを埋め込みベクトル化し、コレクションを検索して、最も近いレンダリング画像とメタデータを返します。
これは、正確なファイル名ではなく意味的な意図で検索したいクリエイティブチームにとって特に便利です。たとえば、デザイナーはファイル名が char_f_warrior_01 なのか f_warrior_blue なのかを記憶しておく必要はありません。単に "女性戦士 青い鎧" と検索するだけで済みます。これが、単なるファイルアーカイブと、実際のアセット検索システムとの違いです。
画像検索
画像検索は、ユーザーが参考画像(リファレンス画像)を持っており、視覚的に類似した 3D アセットを探したい場合に便利です。
たとえば、ゲームアーティストが様式化された(stylized)盾の参考画像をアップロードし、既存のライブラリから類似した Tripo 生成のプロップ(小道具)を検索できます。何百もの画像を手動でブラウズする代わりに、システムはアップロードされた参考画像の視覚的構造、スタイル、またはオブジェクトのコンセプトに一致するアセットを即座に取得できます。
テキスト + 画像検索
テキストと画像を組み合わせた検索は、最も柔軟なオプションです。ユーザーは意味的な意図と視覚的なガイドを組み合わせることができます。
たとえば、ユーザーが剣の参考画像をアップロードし、さらに "青い宝石が付いたファンタジー風の剣" というテキストクエリを追加します。画像が視覚的な参考を提供し、テキストが検索意図を絞り込みます。これにより、どちらか一方の入力だけを使用するよりも、より具体的な検索結果を得ることができます。
以下は簡略化された検索ロジックです:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
返される結果には類似度スコアとメタデータの両方が含まれるため、フロントエンドのインターフェースで一致したアセットのプレビューを表示することが可能です。
検索は純粋なベクトル類似度だけに限定されないことに注目してください。すべてのアセットは構造化されたメタデータ(カテゴリ、スタイル、ユースケースなど)も保持しているため、1 回のリクエストでセマンティック類似度とメタデータ条件を組み合わせることができます。たとえば、「female(女性)」を検索しつつ、結果を llm_use_case == "game asset" に制限することができます。これが メタデータフィルタリング付き検索(filtered search) であり、単なるベクトルの集まりをクエリ可能なアセットカタログへと変える要素です。将来的に複数のシグナルを同時にマッチさせたい場合、Zilliz Cloud はアセットごとの複数の埋め込みにわたるマルチベクトルハイブリッド検索もサポートしています。
例 1: テキストとユースケースによる検索
デモでは、テキスト "female" にユースケースフィルター llm_use_case == "game asset" を適用し、limit=12 に設定して検索を行う例を示しています。
これにより、「女性(female)」に意味的に関連し、かつゲームアセットのユースケースに属する、上位 12 個の一致するアセットが取得されます。
このタイプの検索は、大規模な社内ライブラリからキャラクターコンセプト、NPC デザイン、デフォルメされたアバター、または人型のアセットを迅速に見つけ出す必要があるゲーム開発のパイプラインで非常に役立ちます。
例 2: テキストと参考画像による検索
もう一つの例は、テキストクエリと参考画像を組み合わせたものです。
テキストクエリは、"詳細な装飾と発光エフェクトを持つファンタジー調の武器" です。このクエリには視覚的な参考画像も含まれています。システムはテキストと画像を合わせた共同埋め込み(joint embedding)を生成し、同じベクトルフィールドを検索して、最も関連性の高いレンダリング画像を返します。
これは、ユーザーの意図がテキストだけでは表現しきれないほど具体的な場合に便利です。ビジュアルアセットの検索において、「これに似ているけれど、もっとこういう感じのもの」というアプローチは、クリエイターがまさに考える方法そのものです。
なぜこのワークフローが重要なのか
ここでの本当の価値は、単なる画像検索だけではありません。再利用可能な AI 3D アセットインフラストラクチャを構築できる点にあります。Tripo が高速な生成を担い、Zilliz Cloud がベクトルストレージ、類似性検索、メタデータ取得、そしてマルチモーダル検索の背後にあるデータレイヤーを処理します。これらを組み合わせることで、孤立していた 3D の出力結果が、整理され、検索可能で、再利用可能なライブラリへと変わり、大規模に 3D コンテンツを制作するチームの生産効率が直接的に向上します。
Zilliz Cloud は本番環境の AI 向けに構築されているため、このパターンは小規模から始めてチームの規模に合わせてスケールさせることができます。ゲームスタジオはキャラクター、プロップ、環境のバリエーションを素早く特定でき、EC チームは製品モデルをカテゴリ、色、素材ごとに整理でき、マーケティングチームは再生成する代わりに既存のビジュアルを再利用でき、クリエイティブ運用チームはプロジェクト間で承認済みアセットの検索可能な中央リポジトリを維持できます。
結論
AI による 3D 生成は今や非常に高速になり、制作プロセスにおいて「作る」ことだけがボトルネックではなくなりました。次の課題は、モデルが生成された後に何が起こるかです。つまり、フォルダの奥深くに消えてしまうのではなく、どのように保存され、再発見され、管理され、再利用されるかという点です。
このワークフローは、Tripo と Zilliz Cloud を連携させることで、まさにその課題を解決します。Tripo がテキストや参考画像から高品質なアセットを生成し、Zilliz Cloud が検索レイヤー(レンダリング画像、マルチモーダル埋め込み、構造化メタデータ、スケーラブルなベクトル検索)を提供します。言い換えれば、Tripo が 3D 制作エンジンとなり、Zilliz Cloud がそれらの創作物を検索可能で再利用可能な状態に保ち、次のプロジェクトへ即座に投入できるようにする AI データインフラストラクチャとなります。
実際に試してみる
AI による 3D 生成は最初のステップに過ぎません。真のメリットは、生成されたアセットを、チームやプロジェクト間でスケールする構造化された検索可能システムへと変換することから得られます。Tripo を使用すれば、テキストプロンプトや参考画像から高品質な 3D アセットを生成できます。そして Zilliz Cloud を使用すれば、本番環境の AI ワークフロー向けに設計されたマネージドな Vector Lakebase を基盤として、テキストと画像にまたがるマルチモーダルベクトル検索を通じてそれらを整理し、取得することができます。
- Zilliz Cloud にサインアップして、無料ティアでこのチュートリアルを最初から最後まで体験してください。
- Tripo で 3D アセットを生成する
