CVPR 2025|Tripo AIと北京航空航天大学がMIDIをオープンソース化:単一画像から構成的な3Dシーンを生成

本研究は、VAST、北京航空航天大学、清華大学、香港大学の研究者によって主導されました。筆頭著者は北京航空航天大学の修士課程学生であるZehuan Huang氏で、ジェネレーティブAIと3Dビジョンを研究しています。責任著者(Corresponding Authors)はVASTのチーフサイエンティストであるYanpei Cao氏と北京航空航天大学の准教授であるLv Sheng氏です。
Soraが世界モデルに革命を起こし、物理世界のデジタル基盤としての3Dシーンは、動的でインタラクティブなAIシステムを構築するための重要なインフラとなりつつあります。単一画像から3Dアセットを生成する現在のブレークスルーは、3Dコンテンツ制作における「想像から3Dへ」という原子的な能力を提供しました。
しかし、技術が複合シーン生成へと進化するにつれて、単一オブジェクト生成パラダイムの限界が明らかになってきています。既存の手法は、散らばった「デジタル原子」のような3Dアセットを生成し、合理的な空間関係を持つ「分子構造」へと自己組織化させるのに苦労しています。これにより、いくつかの中心的な課題が生じます。①インスタンス分離のジレンマ(単一の視点から重なり合うオブジェクトを正確に分離する方法)、②物理的制約のモデリング(非現実的な交差や衝突を回避する方法)、③シーンレベルのセマンティック理解(オブジェクトの機能と空間レイアウトの一貫性を維持する方法)。これらのボトルネックは、「デジタル原子」から「インタラクティブな世界」を効率的に構築することを著しく妨げています。
最近、北京航空航天大学、VASTなどの研究チームは、単一画像から幾何学的品質が高く、インスタンス分離可能な3D複合シーンを生成できる新しいモデル、MIDIを導入しました。これにより、単一視点からの3Dシーン生成において画期的な進歩を遂げ、インタラクティブな世界を生成するための基盤を築きました。

- 論文: https://arxiv.org/abs/2412.03558
- プロジェクトページ: https://huanngzh.github.io/MIDI-Page/
- コード: https://github.com/VAST-AI-Research/MIDI-3D
- オンラインデモ: https://huggingface.co/spaces/VAST-AI/MIDI-3D
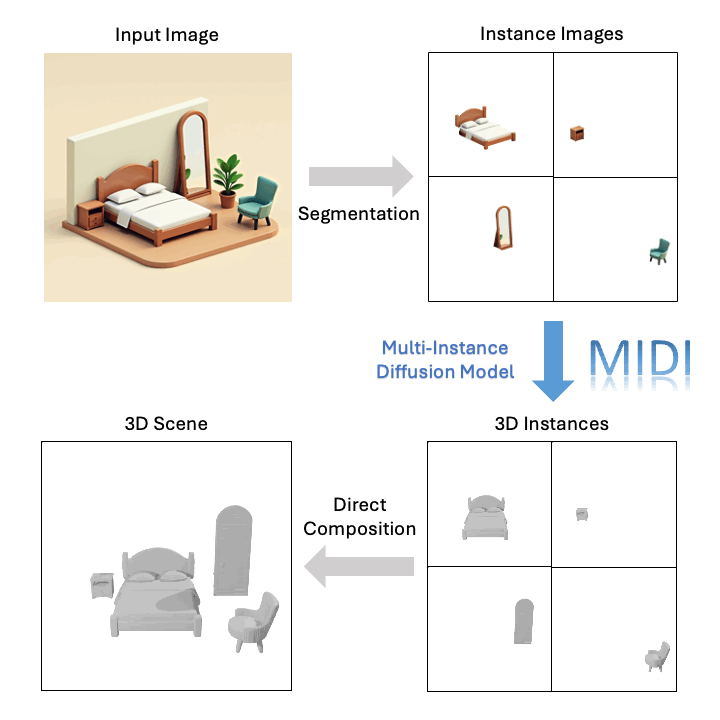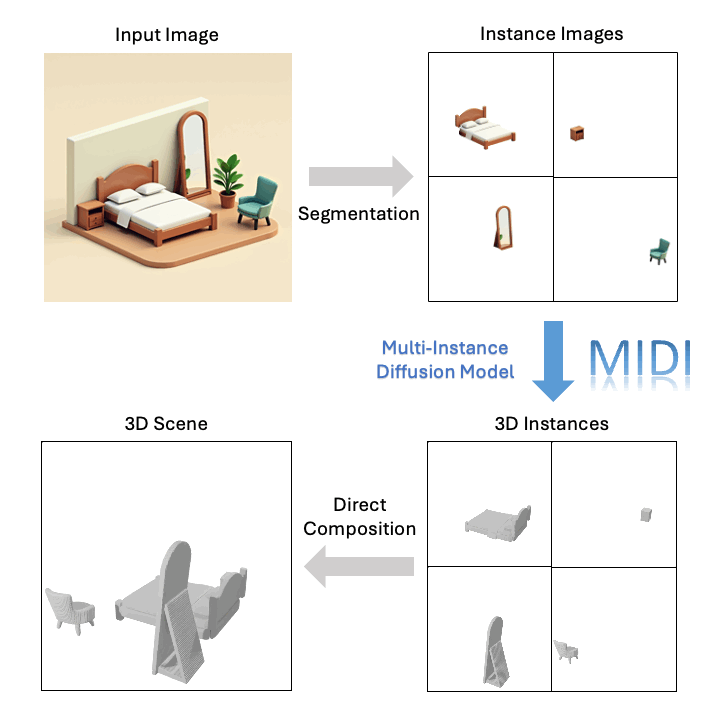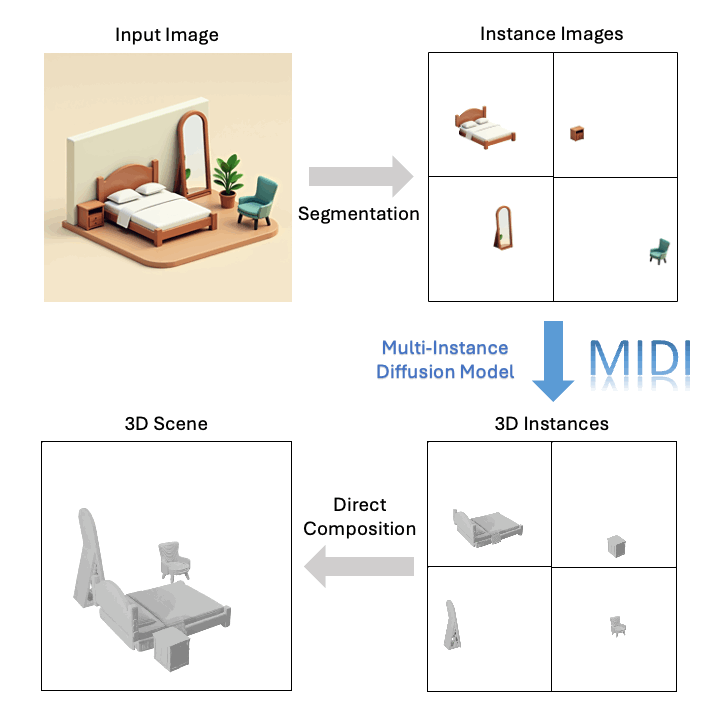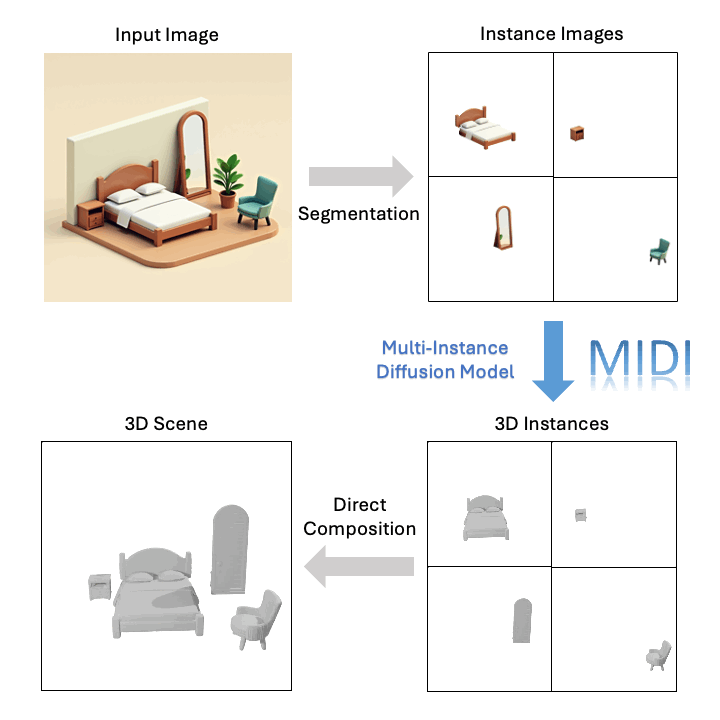
技術的ブレークスルー
従来の構成的な3Dシーン再構築技術は、多くの場合、多段階のオブジェクトごとの生成とシーン最適化に依存しており、プロセスが長く、幾何学的品質が低く、空間レイアウトが不正確なシーンが生成されることがよくありました。これらの問題に対処するため、**MIDI(Multi-Instance Diffusion Model)**は、3Dオブジェクト生成モデルを革新的に活用し、複数の3Dインスタンスを正確な空間関係で同時に生成できるマルチインスタンス拡散モデルに拡張することで、効率的かつ高品質な3Dシーン生成を実現しました。
- 単一オブジェクトからマルチインスタンス生成へ: 複数の3Dインスタンスの潜在表現を同時にノイズ除去し、ノイズ除去プロセス中にマルチインスタンス間の相互作用を導入することで、MIDIは3Dオブジェクト生成モデルを拡張し、相互作用モデリングを伴う複数のインスタンスを同時に生成し、それらを直接3Dシーンに結合します。
- マルチインスタンス自己注意メカニズム: オブジェクト生成モデルの自己注意メカニズムをマルチインスタンス自己注意に拡張することで、MIDIは生成プロセス中にインスタンス間の空間相関とシーン全体の整合性を効果的に捉え、シーンごとの最適化を不要にします。
- トレーニング中のデータ拡張: 限られたシーンデータを用いて3Dインスタンス間の相互作用を監視しつつ、オブジェクトデータでトレーニングを拡張することで、MIDIは事前学習の汎化能力を維持しながらシーンレイアウトを効果的にモデル化します。
生成結果
単一の画像に基づいて、MIDIは高品質な構成的3Dシーンを生成できます。




オンラインデモ
優れたパフォーマンス
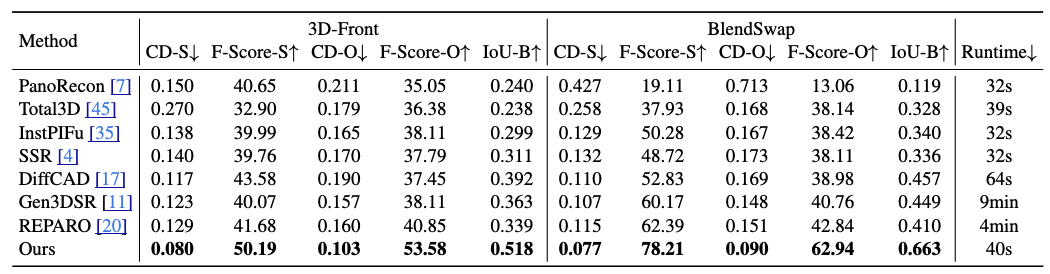
MIDIは、正確な空間レイアウトモデリング、優れた幾何学的生成品質、生成効率、および幅広い適用性を特徴としています。実験結果は、このモデルが複数のデータセットで既存の手法を上回り、3Dインスタンスの空間関係、3Dインスタンスの幾何学的品質、およびエンドツーエンドの生成速度において優れたパフォーマンスを達成していることを示しています。
アプリケーション:3Dシーンコンテンツ制作の新たなツール
MIDIは、3Dシーン制作のための新しいソリューションを提供します。この技術は、建築設計、バーチャルリアリティ、映画の特殊効果、ゲーム開発など、さまざまな分野で大きな可能性を秘めています。高精度、高幾何学的品質の3Dシーン生成能力を持つMIDIは、複雑なシーンにおける高品質なコンテンツの需要を満たし、クリエイターにより多くの可能性を提供します。
Tripo:AIパワード3Dモデルジェネレーター
MIDIが3Dシーンの構成に革命をもたらす中、Tripoは最先端のAI機能で個々のアセット作成を強化します。
単一画像から3Dモデルへ
- 単一の2D画像を高品質な3Dモデルに即座に変換します。
- AIパワードの再構築により、正確な形状とテクスチャを保証します。
- 迅速なプロトタイピングやコンセプトの視覚化に最適です。

複数画像から3Dモデルへ
- さまざまな角度からの複数の画像を使用して、深度と詳細を向上させます。
- 幾何学的精度とリアリズムを高めます。
- 正確なオブジェクトモデリングや製品設計に最適です。

テキストから3Dモデルへ
- シンプルなテキスト記述から3Dモデルを生成します。
- AIがプロンプトを解釈し、詳細でクリエイティブなアセットを作成します。
- ゲーム、VR、アニメーションのコンセプト生成を加速します。

自動リギング&アニメーション
- 最小限の労力でモデルをアニメーション用に即座にリギングします。
- AI駆動のボーン構造とモーション生成。
- モデルをゲーム対応にし、シームレスな統合を実現します。

今後の展望
モデルは優れたパフォーマンスを示していますが、MIDI開発チームは、改善と探求の余地がまだ多くあることを認識しています。例えば、複雑なインタラクティブシーンへの適応性をさらに最適化し、オブジェクト生成の詳細度を向上させることは、今後の主要な焦点です。チームは、継続的な改善と洗練を通じて、この研究方向が単一視点からの複合3Dシーン生成技術の進歩を推進するだけでなく、3D技術の実用アプリケーションにおける普及にも貢献することを期待しています。




