CVPR 2025|Tripo AI与北京航空航天大学开源MIDI:从单张图像生成组合式3D场景

该工作由VAST、北京航空航天大学、清华大学和香港大学的研究人员共同完成。第一作者为北京航空航天大学硕士生黄泽寰,研究方向为生成式AI与3D视觉。通讯作者为VAST首席科学家曹岩培和北京航空航天大学副教授盛律。
随着Sora点燃世界模型的革命,3D场景作为物理世界的数字基石,正成为构建动态交互式AI系统的关键基础设施。当前从单张图像生成3D资产的突破,为3D内容创作提供了“从想象到3D”的原子能力。
然而,随着技术向复合场景生成演进,单物体生成范式的局限性日益凸显。现有方法生成的3D资产如同散落的“数字原子”,难以自组织成具有合理空间关系的“分子结构”。这导致了几个核心挑战:① 实例分离困境(如何从单视图准确解耦重叠物体);② 物理约束建模(如何避免不切实际的交叉和碰撞);③ 场景级语义理解(如何保持物体功能与空间布局的一致性)。这些瓶颈严重阻碍了“数字原子”高效构建“交互世界”的进程。
近日,北京航空航天大学、VAST等机构的研究团队提出了一种新颖的模型——MIDI,它能从单张图像生成高几何质量、实例可分离的3D复合场景,实现了单视图3D场景生成的突破,为生成交互世界奠定了基础。

- 论文:https://arxiv.org/abs/2412.03558
- 项目主页:https://huanngzh.github.io/MIDI-Page/
- 代码:https://github.com/VAST-AI-Research/MIDI-3D
- 在线演示:https://huggingface.co/spaces/VAST-AI/MIDI-3D
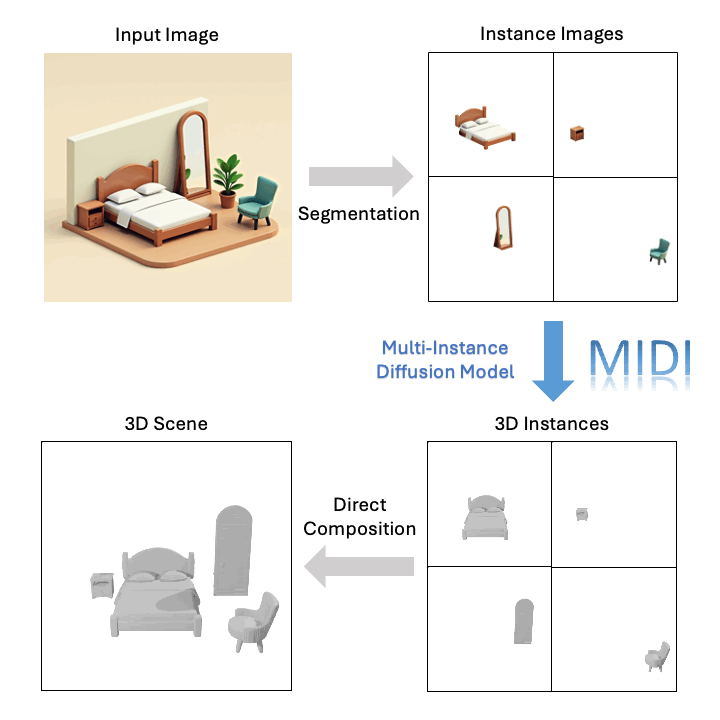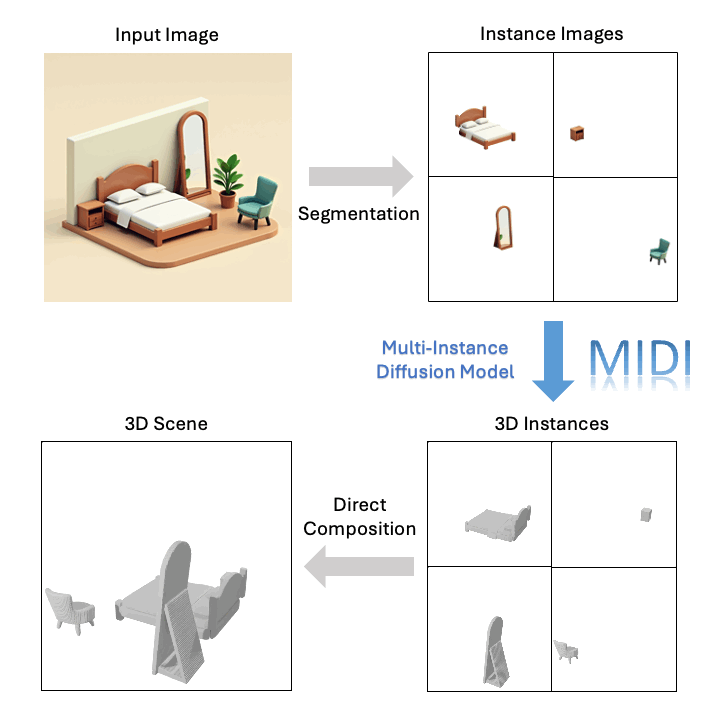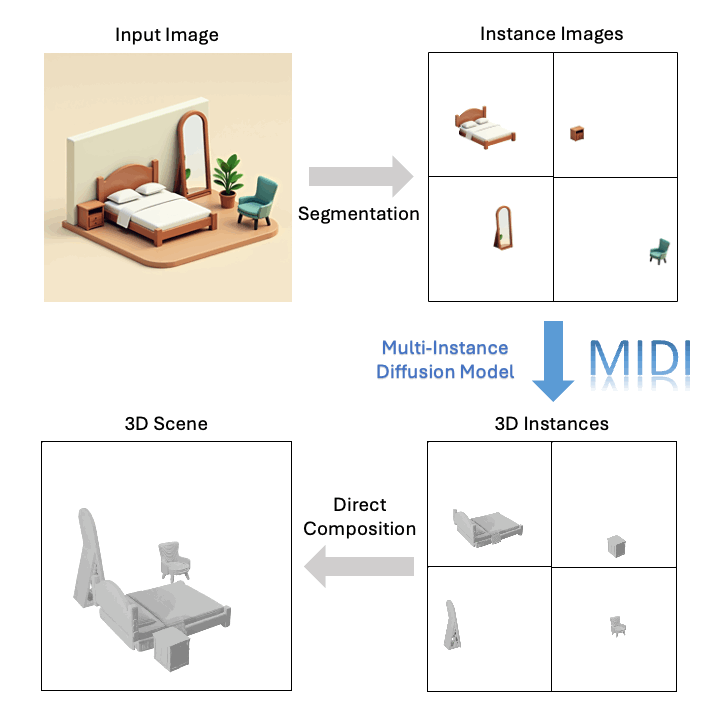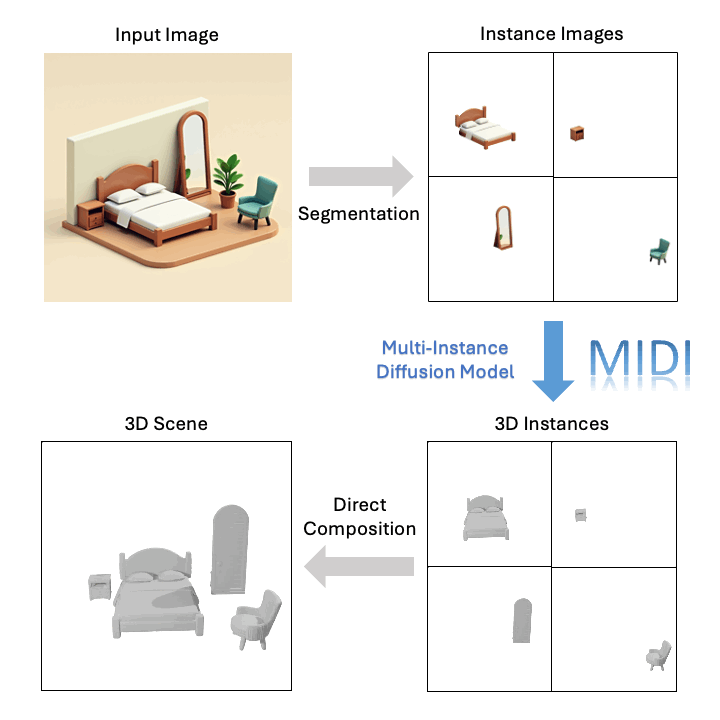
技术突破
传统的组合式3D场景重建技术通常依赖于多阶段、逐个物体生成和场景优化,导致过程冗长,且常生成几何质量低、空间布局不准确的场景。为解决这些问题,**MIDI(Multi-Instance Diffusion Model)**创新性地利用3D物体生成模型,将其扩展为多实例扩散模型,能够同时生成多个具有精确空间关系的3D实例,实现高效高质量的3D场景生成:
- 从单物体到多实例生成: MIDI通过同时去噪多个3D实例的潜在表示,并在去噪过程中引入多实例Token之间的交互,将3D物体生成模型扩展到同时生成多个具有交互建模能力的实例,再直接组合成3D场景。
- 多实例自注意力机制: 通过将物体生成模型的自注意力机制扩展到多实例自注意力,MIDI在生成过程中有效捕捉实例间的空间关联和整体场景的连贯性,无需进行逐场景优化。
- 训练时的数据增强: MIDI在有限的场景数据上监督3D实例之间的交互,同时通过物体数据增强训练,有效建模场景布局,同时保持预训练的泛化能力。
生成结果
基于单张图像,MIDI可以生成高质量的组合式3D场景:




在线演示
卓越性能
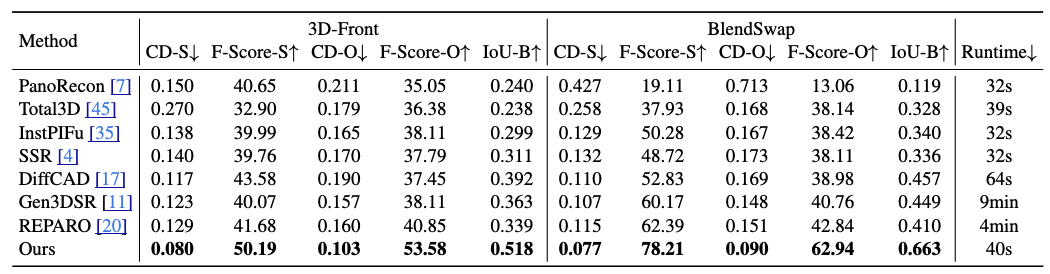
MIDI以其精确的空间布局建模、卓越的几何生成质量、生成效率和广泛适用性为特点。实验结果表明,该模型在多个数据集上超越现有方法,在3D实例空间关系、3D实例几何质量和端到端生成速度方面均取得了优异性能。
应用:3D场景内容创作的新工具
MIDI为3D场景创作提供了一种新颖的解决方案。这项技术在建筑设计、虚拟现实、电影特效和游戏开发等多个领域展现出巨大潜力。凭借其高精度、高几何质量的3D场景生成能力,MIDI能够满足复杂场景对高质量内容的需求,为创作者提供更多可能性。
Tripo:AI驱动的3D模型生成器
当MIDI革新3D场景组合时,Tripo则通过尖端AI能力提升单个资产的创建:
单张图像生成3D模型
- 立即将单张2D图像转换为高质量3D模型。
- AI驱动的重建确保精确的形状和纹理。
- 适用于快速原型设计和概念可视化。

多张图像生成3D模型
- 使用不同角度的多张图像,以获得更好的深度和细节。
- 增强几何精确度和真实感。
- 完美适用于精确物体建模和产品设计。

文本生成3D模型
- 通过简单的文本描述生成3D模型。
- AI解读提示词,创建详细、富有创意的资产。
- 加快游戏、VR和动画的概念生成。

自动绑定与动画
- 轻松实现模型即时绑定,省时省力。
- AI驱动的骨骼结构和动作生成。
- 使模型游戏就绪,实现无缝集成。

未来工作
尽管模型表现出色,MIDI开发团队仍认识到在许多方面仍有改进和探索的空间。例如,进一步优化对复杂交互场景的适应性,以及提升物体生成细节,是未来努力的关键方向。团队希望通过持续改进和完善,该研究方向不仅能推动单视图复合3D场景生成技术的进步,也能为3D技术在实际应用中的广泛普及做出贡献。




