Tripo와 Zilliz로 검색 가능한 AI 3D 에셋 라이브러리 구축하기
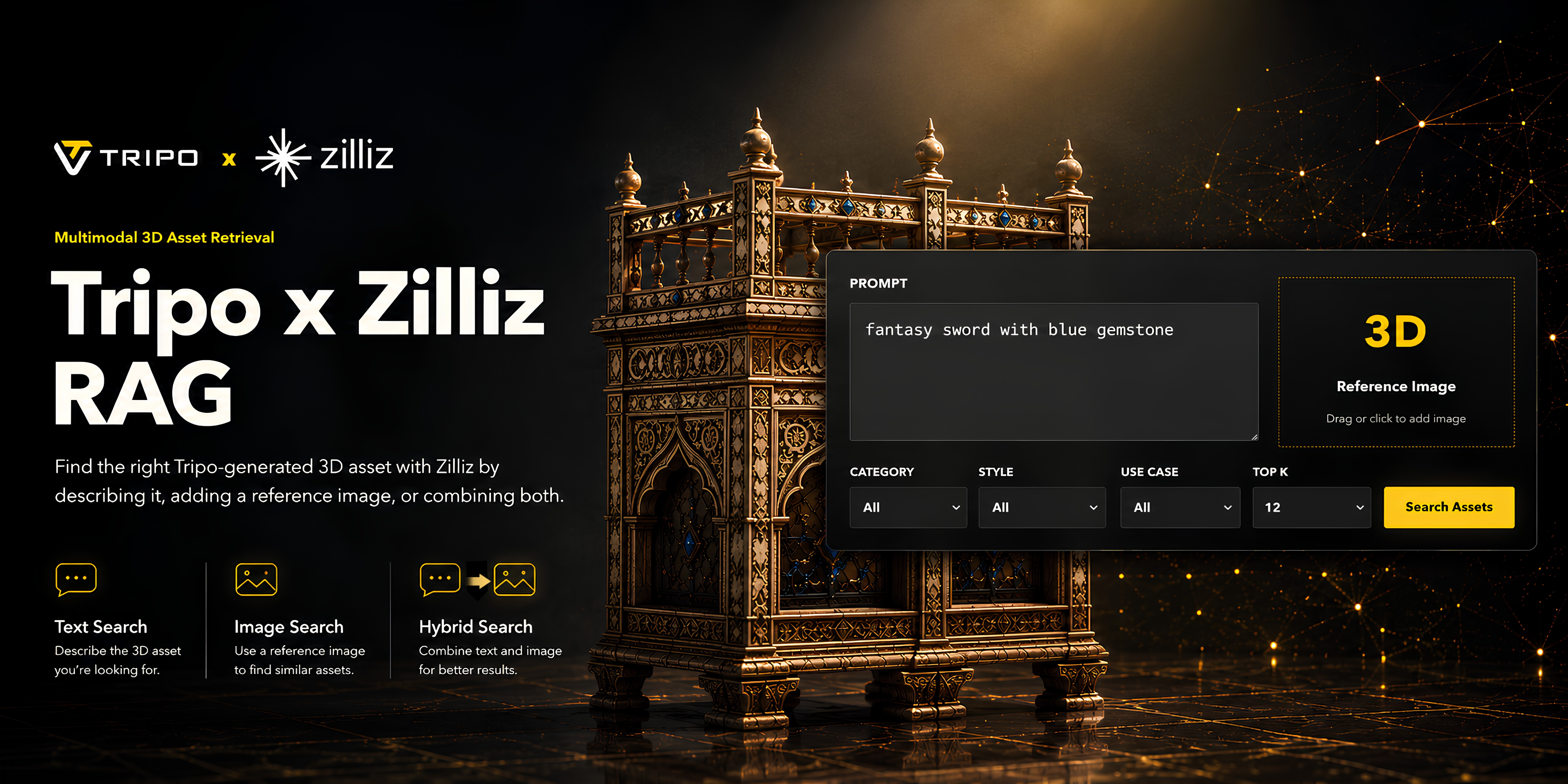
AI 3D 생성 기술 덕분에 팀이 대규모로 3D 에셋을 제작하는 것이 훨씬 쉬워졌습니다. 제작자는 Tripo를 사용하여 텍스트 프롬프트나 레퍼런스 이미지로부터 고품질 3D 모델을 생성할 수 있으며, 이는 게임 개발, 이커머스 시각화, 마케팅 제작, 컨셉 디자인 및 내부 크리에이티브 워크플로우에 매우 유용합니다.
하지만 생성된 에셋의 수가 늘어나면 새로운 문제가 발생합니다.
원하는 3D 에셋을 어떻게 신속하게 찾을 수 있을까요?
팀이 보유한 모델이 몇 개에 불과할 때는 폴더 이름이나 수동 브라우징으로도 충분할 수 있습니다. 하지만 생성된 에셋이 수백, 수천 개로 늘어나면 전통적인 파일 관리 방식은 한계에 부딪히기 시작합니다. 디자이너가 유사한 에셋을 반복해서 생성할 수도 있고, 게임 팀이 유용한 캐릭터나 프롭(prop) 변형 버전을 놓칠 수도 있습니다. 마케팅 팀은 에셋을 사용하는 시간보다 찾는 데 더 많은 시간을 허비하게 될 것입니다.
바로 이 지점에서 검색 가능한 AI 3D 에셋 라이브러리가 빛을 발합니다.
이 워크플로우에서 Tripo는 3D 에셋을 생성하고, Zilliz Cloud는 멀티모달 벡터 및 메타데이터의 검색 레이어 역할을 합니다. Zilliz Cloud는 각 렌더 이미지(render image)를 나타내는 임베딩(embedding)을 저장하고, 이를 카테고리, 스타일, 색상, 오브젝트 타입, 사용 사례 및 소스 파일과 같은 유용한 필드와 연결합니다. 그 결과 사용자는 텍스트, 레퍼런스 이미지 또는 두 가지 모두를 사용해 검색하고, 정형화된 메타데이터가 포함된 매칭되는 Tripo 생성 렌더 이미지를 결과로 받아볼 수 있는 경량 멀티모달 검색 시스템을 갖추게 됩니다.
Zilliz는 AI 데이터 인프라 기업이자 본 워크플로우의 기반이 되는 오픈소스 벡터 데이터베이스인 Milvus의 개발사입니다. Milvus는 RAG, AI 에이전트, 멀티모달 검색, 추천 시스템, 기업 지식 베이스, 시맨틱 검색, 콘텐츠 중복 제거 등 프로덕션 환경의 AI 사용 사례를 위해 구축되었습니다. 또한 Linux Foundation AI & Data의 졸업 프로젝트로, 44,000개 이상의 GitHub 스타와 1억 회 이상의 Docker 다운로드 수를 기록하고 있어, 비정형 데이터의 벡터 임베딩을 저장하고 검색하기 위한 친숙하고 신뢰할 수 있는 기반을 팀에 제공합니다.
이는 Tripo 사용자에게 매우 중요한데, 각 3D 에셋이 단순히 하나의 파일에 그치지 않기 때문입니다. 각 모델은 렌더 프리뷰, 입력 레퍼런스 이미지, 캡션, 태그, 카테고리, 색상, 사용 사례, 프로젝트 ID 및 URL 등과 연결될 수 있습니다. Zilliz Cloud는 이러한 신호들을 함께 검색할 수 있도록 지원하므로, 늘어나는 AI 생성 모델 라이브러리를 일회성 결과물 폴더가 아닌 재사용 가능한 프로덕션 에셋 시스템으로 전환할 수 있습니다.
검색 가능한 3D 에셋 라이브러리를 구축해야 하는 이유
AI 3D 툴은 제작 속도 면에서 매우 뛰어납니다. 이제 단 한 명의 제작자도 아주 짧은 시간 안에 여러 캐릭터 컨셉, 제품 목업, 프롭, 환경 요소 또는 스타일화된 에셋을 생성할 수 있습니다.
하지만 속도는 수량을 낳고, 수량은 관리 문제를 야기합니다.
검색 가능한 3D 에셋 라이브러리는 다음과 같은 몇 가지 일반적인 문제를 해결하는 데 도움이 됩니다:
- 팀이 중복으로 생성하는 대신 기존 에셋을 신속하게 찾을 수 있습니다.
- 디자이너가 컨셉, 스타일, 색상, 오브젝트 타입 또는 사용 사례별로 검색할 수 있습니다.
- 개발자가 여러 프로젝트에서 3D 에셋을 더욱 효율적으로 재사용할 수 있습니다.
- 크리에이티브 팀이 승인되고 재사용 가능한 비주얼 리소스의 내부 라이브러리를 구축할 수 있습니다.
- 이커머스 또는 마케팅 팀이 제품 형태의 3D 에셋을 카테고리와 스타일별로 정리할 수 있습니다.
AI 생성 3D 파일을 일회성 결과물로 취급하는 대신, 이 워크플로우는 이를 재사용 가능한 에셋 시스템으로 변환합니다.
멀티모달 3D 에셋 검색에 Zilliz Cloud가 적합한 이유
Zilliz Cloud는 Milvus 개발사에서 구축한 완전 관리형 Vector Lakebase 플랫폼입니다. 그 핵심에는 1,000억 개 규모에서 높은 처리량과 낮은 지연 시간으로 벡터 검색을 수행할 수 있는 프로덕션 등급의 벡터 데이터베이스가 있습니다. Zilliz Cloud는 이 핵심 기능을 중심으로 멀티모달 데이터 레이크의 개방성, 확장성, 경제성을 결합하여 벡터 검색의 범위를 확장함으로써, 팀이 프로덕션 AI를 위한 비정형 데이터를 검색, 분석 및 거버넌스할 수 있는 단일 플랫폼을 제공합니다.
이는 데이터가 본질적으로 멀티모달인 Tripo 에셋 라이브러리에 적합합니다. 검색 가능한 3D 카탈로그는 렌더 이미지, 레퍼런스 이미지, 텍스트 캡션, 생성된 메타데이터, 팀 소유권 필드 및 프로젝트별 태그를 동시에 처리해야 할 수 있습니다. Zilliz Cloud는 벡터 검색과 메타데이터 검색을 통해 이러한 신호들을 연결하므로, 사용자는 의미(semantic), 시각적 유사성, 구조화된 필터 또는 이 세 가지 모두를 결합하여 에셋을 찾을 수 있습니다.
Zilliz는 From Vector Database to Vector Lakebase 및 Why We Built Vector Lakebase에서 이러한 제품의 진화 과정을 설명합니다. 핵심 개념은 현대적인 AI 시스템에는 최근접 이웃(nearest-neighbor) 검색 이상의 기능이 필요하다는 것입니다. 즉, 빠르게 증가하는 비정형 데이터셋에 대한 실시간 서빙, 반복적인 탐색, 배치 분석 및 거버넌스를 위한 데이터 기반이 필요합니다. 이러한 요구사항은 팀이 오늘의 최상의 결과를 검색하고 시간이 지남에 따라 카탈로그를 지속적으로 개선하고자 하는 AI 3D 라이브러리의 요구사항과 정확히 일치합니다.
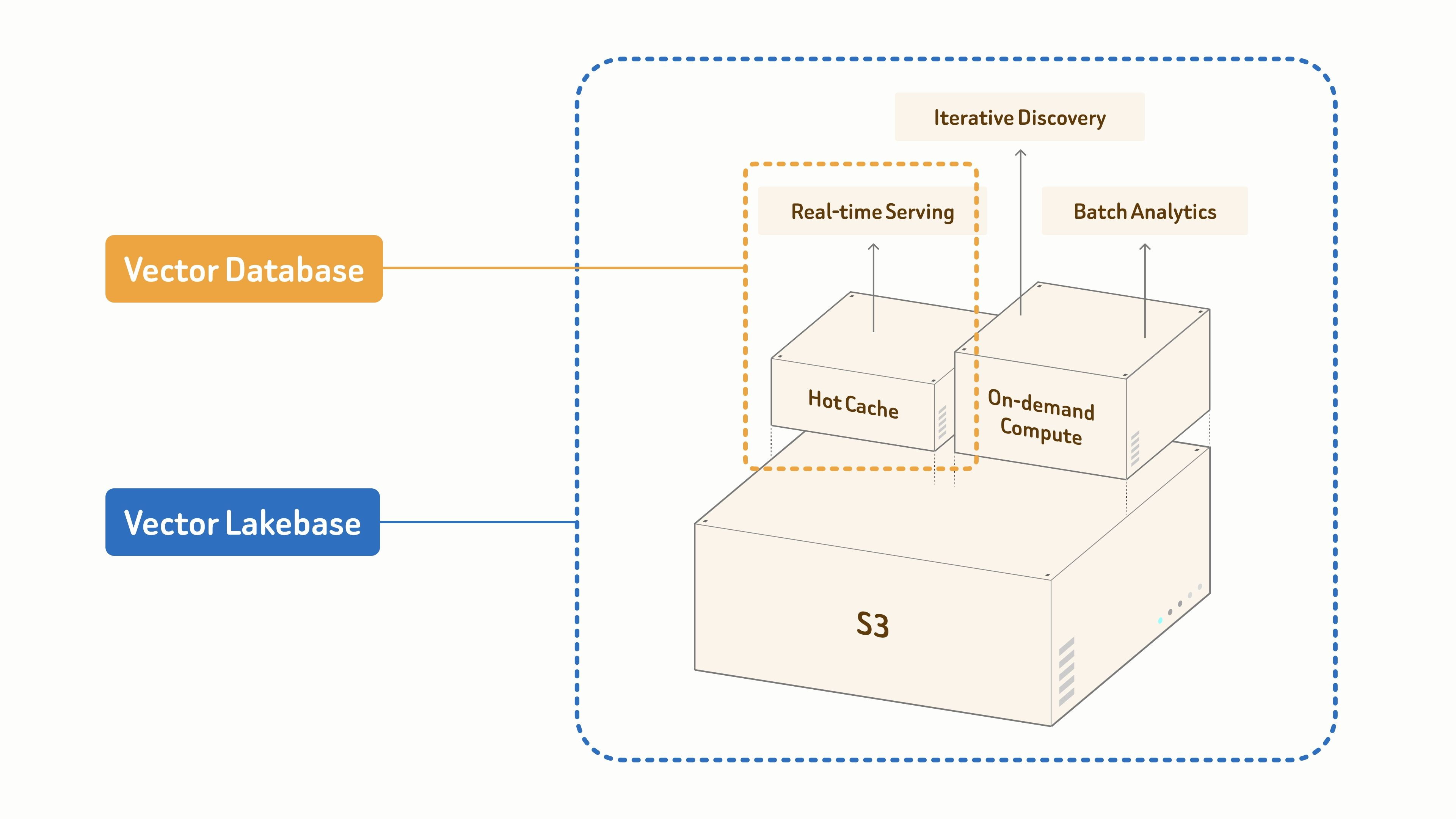
워크플로우 개요
이 데모에서는 세 가지 유형의 로컬 데이터를 사용합니다:
- CSV 파일은 카테고리, 스타일, 오브젝트 타입, 색상, 사용 사례, 파일 이름 및 관련 프로젝트 정보와 같은 각 3D 에셋의 메타데이터를 저장합니다.
- milvus_render_images/ 폴더는 Tripo로 생성된 에셋의 렌더링된 프리뷰 이미지를 저장합니다. 이 렌더 이미지들이 주요 검색 대상입니다.
- milvus_input_images/ 폴더는 image-to-3D 생성 중에 사용된 레퍼런스 이미지를 저장합니다. 이는 주로 메타데이터 및 선택적인 쿼리 레퍼런스로 사용됩니다.
간단히 말해, 이 구성을 통해 사용자는 필요한 것을 설명하거나, 시각적 레퍼런스를 업로드하거나, 두 입력을 결합하여 라이브러리에서 관련 에셋을 찾을 수 있습니다.
사전 준비 사항
시작하기 전에 다음 사항이 준비되었는지 확인하세요:
- Zilliz Cloud 계정. Zilliz Cloud는 Milvus 개발사에서 구축한 완전 관리형 Vector Lakebase 플랫폼입니다. 프로덕션 등급의 벡터 데이터베이스와 멀티모달 데이터를 위한 레이크 네이티브(lake-native) 기반을 결합하여, 벡터 인프라를 직접 운영하지 않고도 임베딩과 구조화된 메타데이터를 저장할 수 있습니다. 무료 티어만으로도 충분히 실습해 볼 수 있습니다. Zilliz Cloud에 가입하고, 무료 클러스터를 생성한 다음 해당 URI와 토큰을 확보하세요.
- 아래에서 사용되는 Gemini 멀티모달 임베딩 모델을 위한 OpenRouter API 키.
- Milvus SDK가 설치된 Python 3.10+ (
pip install -U pymilvus). 처음 접하시는 경우 PyMilvus 설치 가이드를 참조하세요. - Tripo로 생성된 일련의 3D 에셋 — 렌더 프리뷰 이미지 및 선택적으로 image-to-3D 생성에 사용된 레퍼런스 이미지.
1단계: Tripo 생성 3D 에셋 데이터 준비
첫 번째 단계는 Tripo를 통해 생성된 데이터를 준비하는 것입니다.
각 에셋은 최소한 다음 항목을 포함해야 합니다:
- 렌더 프리뷰 이미지
- CSV 내의 메타데이터 행
- 선택적인 입력/레퍼런스 이미지 정보
- 가능한 경우 카테고리, 스타일, 사용 사례, 오브젝트 및 색상 필드
예를 들어, 하나의 에셋은 다음과 같은 메타데이터를 포함할 수 있습니다:
| 필드 | 예시 값 |
|---|---|
| Category | Character |
| Style | Fantasy |
| Object Type | Female warrior |
| Color | Blue, Silver |
| Use Case | Game asset |
| File Name | warrior_female_01.webp |
벡터 검색만으로는 항상 충분하지 않기 때문에 이 메타데이터가 중요합니다. 실제 에셋 라이브러리에서 사용자는 시맨틱 검색과 필터를 결합하고자 하는 경우가 많습니다.
예를 들면 다음과 같습니다:
- "game asset" 사용 사례에서 "female character" 찾기.
- "weapon" 카테고리에서 "fantasy sword with blue gemstone" 찾기.
- realistic, cartoon, sci-fi 또는 low poly와 같은 특정 비주얼 스타일의 에셋 찾기.
메타데이터 구조가 더 잘 설계될수록 에셋 라이브러리의 유용성도 더욱 높아집니다.
임베딩을 위한 이미지 포맷 제한 사항
렌더 이미지와 입력 레퍼런스 이미지는 저장 효율성을 위해 .webp 포맷으로 저장됩니다.
하지만 Gemini 임베딩 모델(gemini-embedding-2-preview)은 PNG 및 JPEG 입력만 안정적으로 지원합니다. WebP 이미지는 API 백엔드에 따라 임베딩 실패를 유발할 수 있습니다.
따라서 임베딩을 생성하기 전에 이미지를 PNG 또는 JPEG로 변환하는 전처리 단계가 필요합니다.
2단계: Zilliz Cloud 컬렉션 생성
Zilliz Cloud에서 컬렉션의 각 레코드는 하나의 Tripo 생성 3D 에셋을 나타냅니다.
여기서 Vector Lakebase 모델이 유용해집니다. 전통적인 벡터 데이터베이스는 실시간 유사도 검색에 탁월합니다. Vector Lakebase는 이러한 검색 경로를 유지하면서 멀티모달 데이터, 배치 분석, 반복적인 탐색 및 거버넌스를 위한 공유된 레이크 네이티브 데이터 기반을 추가합니다. 이 데모에서는 가볍게 사용하지만, 동일한 구조로 훨씬 더 큰 규모의 Tripo 에셋 라이브러리까지 확장할 수 있습니다.
컬렉션은 구조화된 메타데이터와 멀티모달 벡터를 모두 저장합니다. 핵심 벡터 필드는 multimodal_vector입니다. 이 데모에서 벡터 차원은 3072이며, 유사도 메트릭으로는 COSINE이 사용됩니다.
텍스트, 이미지, 그리고 텍스트+이미지 쿼리가 동일한 벡터 공간으로 임베딩되기 때문에, 시스템은 하나의 통합된 벡터 필드를 사용하여 모든 에셋을 검색할 수 있습니다.
다음은 간소화된 스키마 설정입니다:
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
그 다음 벡터 인덱스를 생성합니다:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
스키마와 인덱스를 정의한 후 다음을 실행합니다:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
명령이 완료되면 Zilliz Cloud 콘솔에서 컬렉션을 확인할 수 있습니다.
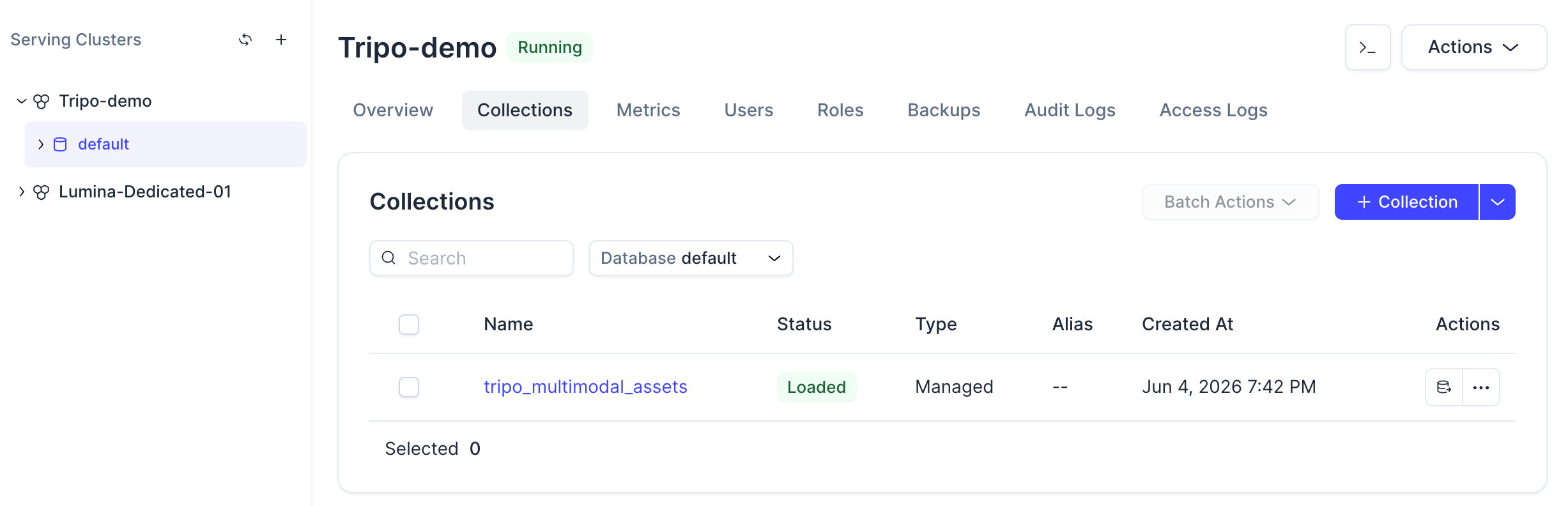
컬렉션을 클릭하면 상태, 스키마, 로드된 엔티티 및 벡터 필드 구성을 볼 수 있습니다.
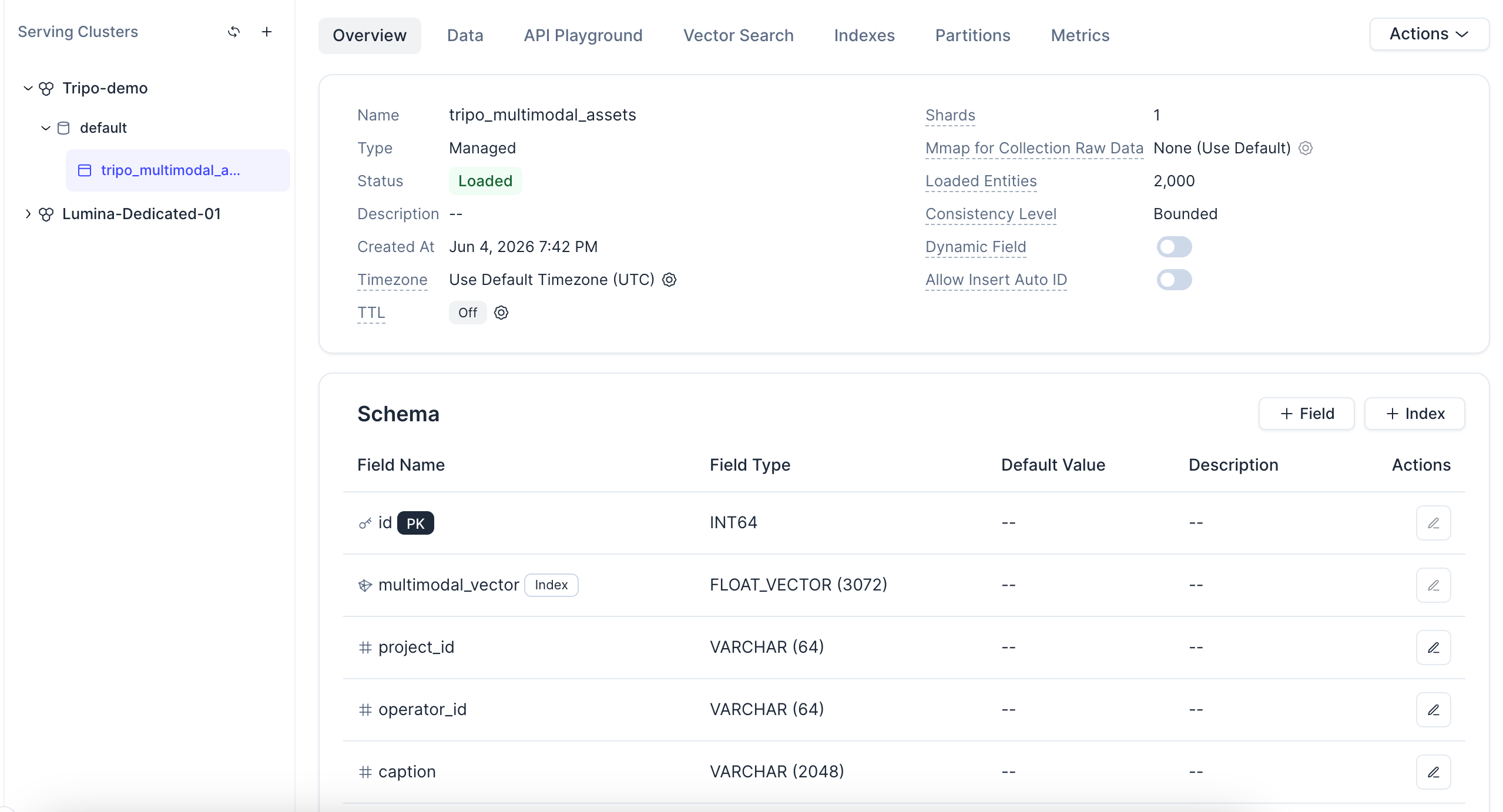
인덱스 관련 참고 사항: 이 데모에서는 Zilliz Cloud가 사용자의 데이터를 기반으로 벡터 인덱스를 자동으로 선택하고 튜닝해 주는 AUTOINDEX를 사용하므로, 인덱스 유형이나 파라미터를 직접 고를 필요가 없습니다. COSINE 메트릭 유형은 다음 단계에서 생성되는 L2 정규화(L2-normalized) 임베딩과 일치합니다. 또한 각 레코드가 관리형 컬렉션 내의 하나의 엔티티이기 때문에, 아키텍처를 재설계하지 않고도 수백 개의 에셋에서 수백만 개 규모로 동일한 설정을 확장할 수 있습니다.
3단계: 렌더 이미지의 임베딩 생성
다음으로, Tripo 렌더 프리뷰 이미지에 대한 임베딩을 생성합니다.
이 워크플로우에서는 렌더 이미지를 base64 데이터 URL로 변환하여 임베딩 모델로 전송합니다. 반환된 벡터는 COSINE 유사도 검색에 사용할 수 있도록 정규화됩니다.
핵심 로직은 다음과 같습니다:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
전체 데이터셋에 대한 임베딩 캐시를 빌드하려면 다음을 실행합니다:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
임베딩 생성은 시간이 오래 걸릴 수 있고 API에 의존적이기 때문에 캐싱 단계가 매우 유용합니다. 데이터를 가져올 때마다 임베딩을 생성하는 대신, 캐시를 한 번 빌드한 다음 가져오기 프로세스 중에 재사용할 수 있습니다.

embedding 캐시를 생성한 후, CSV의 각 행은 하나의 Zilliz Cloud 엔티티로 변환됩니다.
각 엔티티는 다음 정보를 포함합니다:
- Asset ID
- Project ID
- Operator ID
- Caption
- LLM이 생성한 메타데이터
- Generation mode
- 렌더링 이미지 파일 정보
- 입력 이미지 파일 정보
- Multimodal vector
다음은 단순화된 엔티티 변환 함수 버전입니다:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
그 다음 전체 데이터셋을 임포트합니다:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
임포트가 완료되면 Zilliz Cloud 콘솔을 열고 Data 탭을 확인합니다. 메타데이터 필드와 벡터 정보를 포함하여 임포트된 에셋 레코드를 확인할 수 있습니다.
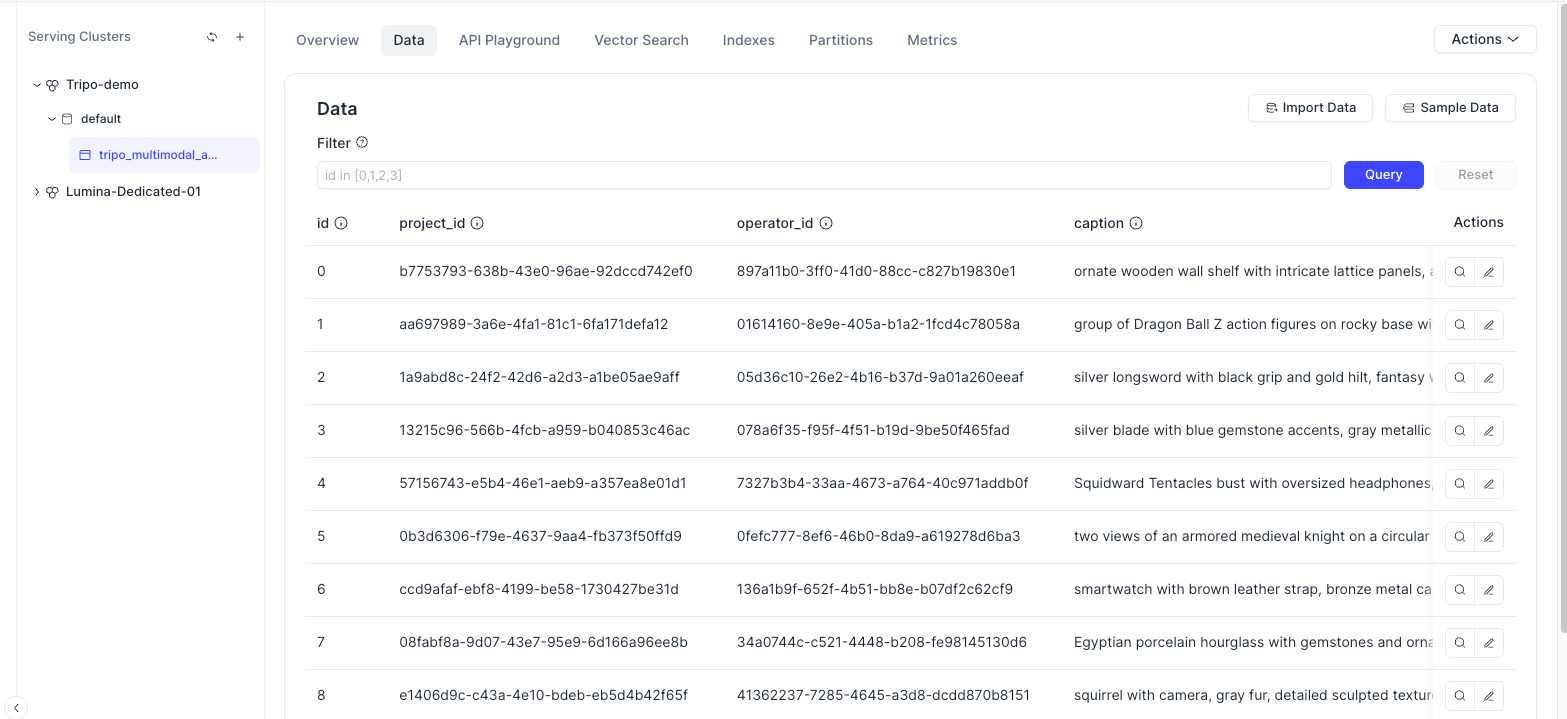
이 시점에서 Tripo로 생성된 3D 에셋은 더 이상 단순한 로컬 파일이 아닙니다. 이제 벡터 데이터베이스에서 검색 가능한 엔티티가 되었습니다.
Step 5: Search the 3D Asset Library
검색 시스템은 세 가지 쿼리 모드를 지원합니다:
- 텍스트 검색 (Text Search) — 의미론적(semantic) 설명을 통한 검색
- 이미지 검색 (Image Search) — 시각적 유사성을 통한 검색
- 텍스트 + 이미지 검색 (Text + Image Search) — 더 정밀한 검색을 위해 두 가지 방식을 결합
세 가지 쿼리 유형 모두 동일한 멀티모달 embedding 모델을 사용하여 벡터로 변환됩니다. 그런 다음 Zilliz Cloud의 multimodal_vector 필드를 대상으로 쿼리 벡터 검색을 수행합니다.
텍스트 검색 (Text Search)
텍스트 검색은 사용자가 원하는 것이 무엇인지 이미 알고 있을 때 유용합니다.
쿼리 예시: "A female character with blue and silver armor" (파란색과 은색 갑옷을 입은 여성 캐릭터)
시스템은 텍스트 쿼리를 임베딩하고, 컬렉션을 검색하여 메타데이터와 함께 가장 유사한 렌더링 이미지를 반환합니다.
이 기능은 정확한 파일 이름 대신 의미론적 의도로 검색하려는 크리에이티브 팀에게 특히 유용합니다. 예를 들어, 디자이너는 파일 이름이 char_f_warrior_01인지 f_warrior_blue인지 기억할 필요가 없습니다. 단순히 *"female warrior blue armor"*라고 검색하면 됩니다. 이것이 단순한 파일 아카이브와 실제 에셋 검색 시스템의 차이점입니다.
이미지 검색 (Image Search)
이미지 검색은 사용자가 참조 이미지를 가지고 있고 이와 시각적으로 유사한 3D 에셋을 찾고자 할 때 유용합니다.
예를 들어, 게임 아티스트가 스타일리시한 방패의 참조 이미지를 업로드하고 기존 라이브러리에서 유사한 Tripo 생성 프롭(prop)을 검색할 수 있습니다. 수백 개의 이미지를 수동으로 찾아보는 대신, 시스템이 업로드된 참조 이미지의 시각적 구조, 스타일 또는 오브젝트 콘셉트와 일치하는 에셋을 검색해 줍니다.
텍스트 + 이미지 검색 (Text + Image Search)
텍스트와 이미지를 결합한 검색은 가장 유연한 옵션입니다. 사용자가 의미론적 의도와 시각적 가이드를 결합할 수 있도록 해줍니다.
예를 들어, 사용자가 검 참조 이미지를 업로드하고 *"fantasy sword with blue gemstone" (파란색 보석이 박힌 판타지 검)*이라는 텍스트 쿼리를 추가할 수 있습니다. 이미지는 시각적 참조를 제공하고, 텍스트는 검색 의도를 좁혀줍니다. 이를 통해 두 입력 중 하나만 사용하는 것보다 더 구체적인 검색이 가능해집니다.
다음은 단순화된 검색 로직입니다:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
반환된 결과에는 유사도 점수와 메타데이터가 모두 포함되어 있어 프론트엔드 인터페이스에 매칭된 에셋의 프리뷰를 표시할 수 있습니다.
검색이 순수 벡터 유사도에만 국한되지 않는다는 점에 주목하세요. 모든 에셋에는 구조화된 메타데이터(카테고리, 스타일, 유스케이스 등)가 함께 저장되므로, 단일 요청에서 의미론적 유사도와 메타데이터 조건을 결합할 수 있습니다. 예를 들어 "female"을 검색하면서 결과를 llm_use_case == "game asset"으로 제한할 수 있습니다. 이것이 바로 **필터링된 검색 (filtered search)**이며, 단순한 벡터 뭉치를 쿼리 가능한 에셋 카탈로그로 전환해 주는 핵심 기능입니다. 나중에 한 번에 여러 신호를 매칭하고 싶다면, Zilliz Cloud는 에셋당 여러 임베딩을 사용하는 다중 벡터 하이브리드 검색(multi-vector hybrid search)도 지원합니다.
예시 1: 텍스트 및 유스케이스로 검색
데모에서는 텍스트 "female"과 유스케이스 필터 llm_use_case == "game asset"을 함께 사용하고 limit=12로 설정한 검색 쿼리 예시를 보여줍니다.
이를 통해 "female"과 의미론적으로 관련이 있고 게임 에셋 유스케이스에 속하는 상위 12개의 일치하는 에셋을 검색합니다.
이러한 유형의 검색은 대규모 내부 라이브러리에서 캐릭터 콘셉트, NPC 디자인, 스타일리시한 아바타 또는 휴머노이드 에셋을 빠르게 찾아내야 하는 게임 개발 파이프라인에서 매우 유용합니다.
예시 2: 텍스트 및 참조 이미지로 검색
또 다른 예시는 텍스트 쿼리와 참조 이미지를 결합한 것입니다.
텍스트 쿼리는 *"Fantasy style weapon with detailed ornamentation and glowing effects" (디테일한 장식과 빛나는 효과가 있는 판타지 스타일 무기)*입니다. 쿼리에는 시각적 참조 이미지도 함께 포함됩니다. 그런 다음 시스템은 텍스트와 이미지를 함께 결합한 하나의 공동 임베딩(joint embedding)을 생성하고, 동일한 벡터 필드를 검색하여 가장 관련성 높은 렌더링 이미지를 반환합니다.
이 방식은 사용자의 의도가 텍스트만으로는 표현하기 너무 구체적일 때 유용합니다. 시각적 에셋 검색의 경우, "이것과 비슷하지만, 저것에 더 가까운 것"이 제작자들이 생각하는 방식인 경우가 많기 때문입니다.
이 워크플로우가 중요한 이유
여기서 진정한 가치는 단순한 이미지 검색이 아닙니다. 재사용 가능한 AI 3D 에셋 인프라를 구축하는 데 있습니다. Tripo는 빠른 생성을 처리하고, Zilliz Cloud는 벡터 저장, 유사도 검색, 메타데이터 검색 및 멀티모달 검색 뒤의 데이터 레이어를 처리합니다. 이 둘이 결합되어 고립된 3D 출력물을 체계적이고 검색 및 재사용이 가능한 라이브러리로 전환하며, 이는 대규모로 3D 콘텐츠를 제작하는 팀의 생산 효율성을 직접적으로 향상시킵니다.
Zilliz Cloud는 프로덕션 AI를 위해 빌드되었기 때문에, 동일한 패턴을 소규모로 시작하여 팀의 성장에 맞춰 확장할 수 있습니다. 게임 스튜디오는 캐릭터, 프롭, 환경 베리에이션을 찾을 수 있고, 이커머스 팀은 제품 모델을 카테고리, 색상 또는 재질별로 정리할 수 있으며, 마케팅 팀은 매번 새로 생성하는 대신 기존 에셋을 재사용할 수 있습니다. 또한 크리에이티브 운영 팀은 여러 프로젝트에 걸쳐 승인된 에셋을 중앙에서 검색 가능한 저장소로 관리할 수 있습니다.
결론
이제 AI 3D 생성 속도가 충분히 빨라져 생성이 유일한 병목 단계가 아닙니다. 다음 과제는 모델이 생성된 이후에 발생합니다. 즉, 폴더 속으로 사라지는 대신 어떻게 저장하고, 다시 찾고, 관리하고, 재사용할 것인가의 문제입니다.
이 워크플로우는 Tripo와 Zilliz Cloud를 연결하여 바로 이 문제를 해결합니다. Tripo는 텍스트나 참조 이미지로부터 고품질 에셋을 생성하고, Zilliz Cloud는 렌더링 이미지, 멀티모달 임베딩, 구조화된 메타데이터, 확장 가능한 벡터 검색을 포함한 검색 레이어를 추가합니다. 즉, Tripo는 3D 생성 엔진이 되고, Zilliz Cloud는 이러한 창작물을 검색 및 재사용 가능하게 유지하여 다음 프로젝트에 바로 사용할 수 있도록 돕는 AI 데이터 인프라가 됩니다.
직접 시도해 보세요
AI 3D 생성은 첫 걸음일 뿐입니다. 생성된 에셋을 여러 팀과 프로젝트에서 확장 가능한 구조화되고 검색 가능한 시스템으로 전환할 때 진정한 가치가 발휘됩니다. Tripo를 사용하면 텍스트 프롬프트나 참조 이미지로부터 고품질 3D 에셋을 생성할 수 있습니다. Zilliz Cloud를 사용하면 프로덕션 AI 워크플로우용으로 설계된 매니지드 Vector Lakebase를 기반으로, 텍스트와 이미지에 걸친 멀티모달 벡터 검색을 통해 에셋을 정리하고 검색할 수 있습니다.
- Zilliz Cloud에 가입하고 프리 티어에서 이 튜토리얼을 처음부터 끝까지 따라해 보세요.
- Tripo로 3D 에셋을 생성해 보세요.
