使用 Tripo 和 Zilliz 构建可搜索的 AI 3D 资产库
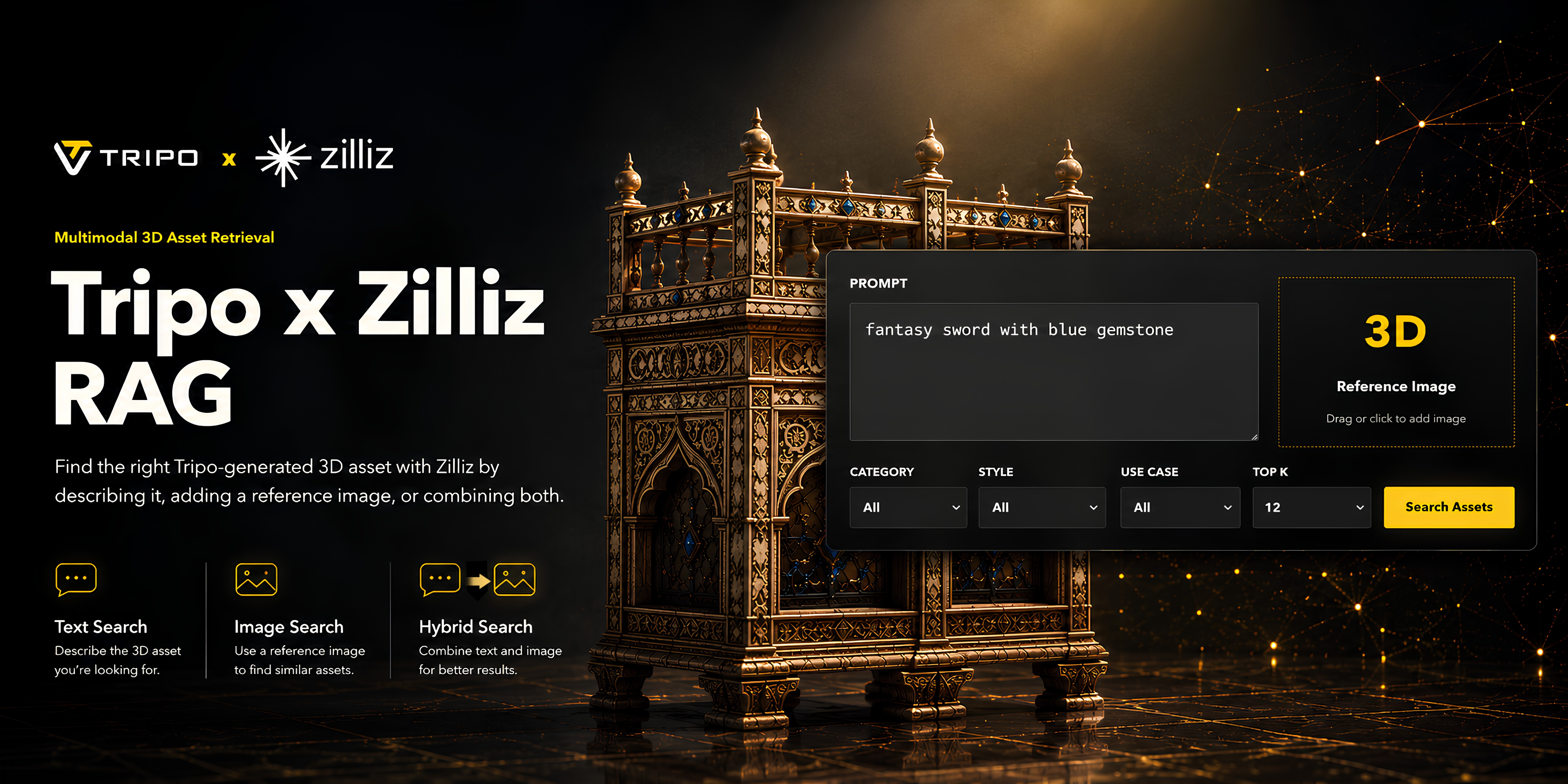
AI 3D 生成技术正在显著降低团队大规模创建 3D 资产的门槛。通过 Tripo,创作者可以根据文本提示词或参考图像生成高质量的 3D 模型,这在游戏开发、电商可视化、营销制作、概念设计以及内部创意工作流中非常实用。
但随着生成的资产数量不断增加,一个新的问题也随之而来。
如何快速找到所需的 3D 资产?
当团队只有少量模型时,文件夹命名和手动浏览或许就足够了。但一旦资产数量达到数百或数千个,传统的文件管理方式就会失效。设计师可能会重复生成类似的资产,游戏团队可能会遗忘已有的角色或道具变体,营销团队花在寻找资产上的时间甚至可能超过使用它们的时间。
这正是可搜索 AI 3D 资产库的价值所在。
在这个工作流中,Tripo 负责生成 3D 资产,而 Zilliz Cloud 则作为多模态向量和元数据的检索层。它存储代表每个渲染图像的嵌入向量(embeddings),并将其与类别、风格、颜色、对象类型、使用场景和源文件等实用字段关联起来。最终构建出一个轻量级的多模态检索系统,用户可以通过文本、参考图像或两者结合进行搜索,并获取匹配的 Tripo 生成渲染图及结构化元数据。
Zilliz 是一家 AI 数据基础设施公司,也是该工作流背后的开源向量数据库 Milvus 的创造者。Milvus 专为生产级 AI 使用场景而设计,如 RAG、AI 智能体(AI agents)、多模态搜索、推荐系统、企业知识库、语义搜索和内容去重。它也是 Linux 基金会 AI & Data 的毕业项目,拥有超过 44,000 颗 GitHub 星标和超过 1 亿次 Docker 拉取,为团队存储和检索非结构化数据的向量嵌入提供了可靠的基础。
这对 Tripo 用户来说至关重要,因为每个 3D 资产不仅仅是一个单一文件。每个模型都可以与渲染预览图、输入参考图、描述、标签、类别、颜色、使用场景、项目 ID 和 URL 相关联。Zilliz Cloud 能够将这些信号整合并提供统一检索,让不断增长的 AI 生成模型库转变为可复用的生产资产系统,而不是一堆一次性的输出文件。
为什么要构建可搜索的 3D 资产库
AI 3D 工具在生产速度上表现优异。现在,单个创作者就能在极短的时间内生成多个角色概念、产品模型、道具、环境元素或风格化资产。
然而,速度带来了数量,数量带来了管理难题。
构建可搜索的 3D 资产库有助于解决以下几个常见问题:
- 团队可以快速找到现有资产,避免重复生成。
- 设计师可以按概念、风格、颜色、对象类型或使用场景进行搜索。
- 开发人员可以更高效地跨项目复用 3D 资产。
- 创意团队可以建立一个经过审核且可复用的内部视觉素材库。
- 电商或营销团队可以按类别和风格组织类似产品的 3D 资产。
这种工作流不再将 AI 生成的 3D 文件视为一次性产出,而是将其转化为一个可复用的资产系统。
为什么 Zilliz Cloud 适合多模态 3D 资产搜索
Zilliz Cloud 是由 Milvus 团队打造的开箱即用向量湖仓(Vector Lakebase)平台。其核心是一个生产级的向量数据库,支持百亿规模下高吞吐、低延迟的向量搜索。围绕这一核心,Zilliz Cloud 结合了多模态数据湖的开放性、可扩展性和经济性,为团队提供了一个统一的平台,用于在生产级 AI 中搜索、分析和管理非结构化数据。
这非常契合 Tripo 资产库的需求,因为这些数据本质上就是多模态的。一个可搜索的 3D 目录可能需要同时处理渲染图、参考图、文本描述、生成的元数据、团队归属字段以及特定项目的标签。Zilliz Cloud 通过向量搜索和元数据检索连接这些信号,让用户能够通过语义、视觉相似度、结构化过滤条件或三者的结合来查找资产。
Zilliz 在《From Vector Database to Vector Lakebase》和《Why We Built Vector Lakebase》中阐述了这一产品演进。其核心思想是,现代 AI 系统不仅需要最近邻搜索(nearest-neighbor search),还需要一个数据基础来支持实时服务、迭代探索、批处理分析以及对快速增长的非结构化数据集的治理。这些需求直接映射到了 AI 3D 库中,团队希望在检索出当前最佳结果的同时,能持续优化资产目录。
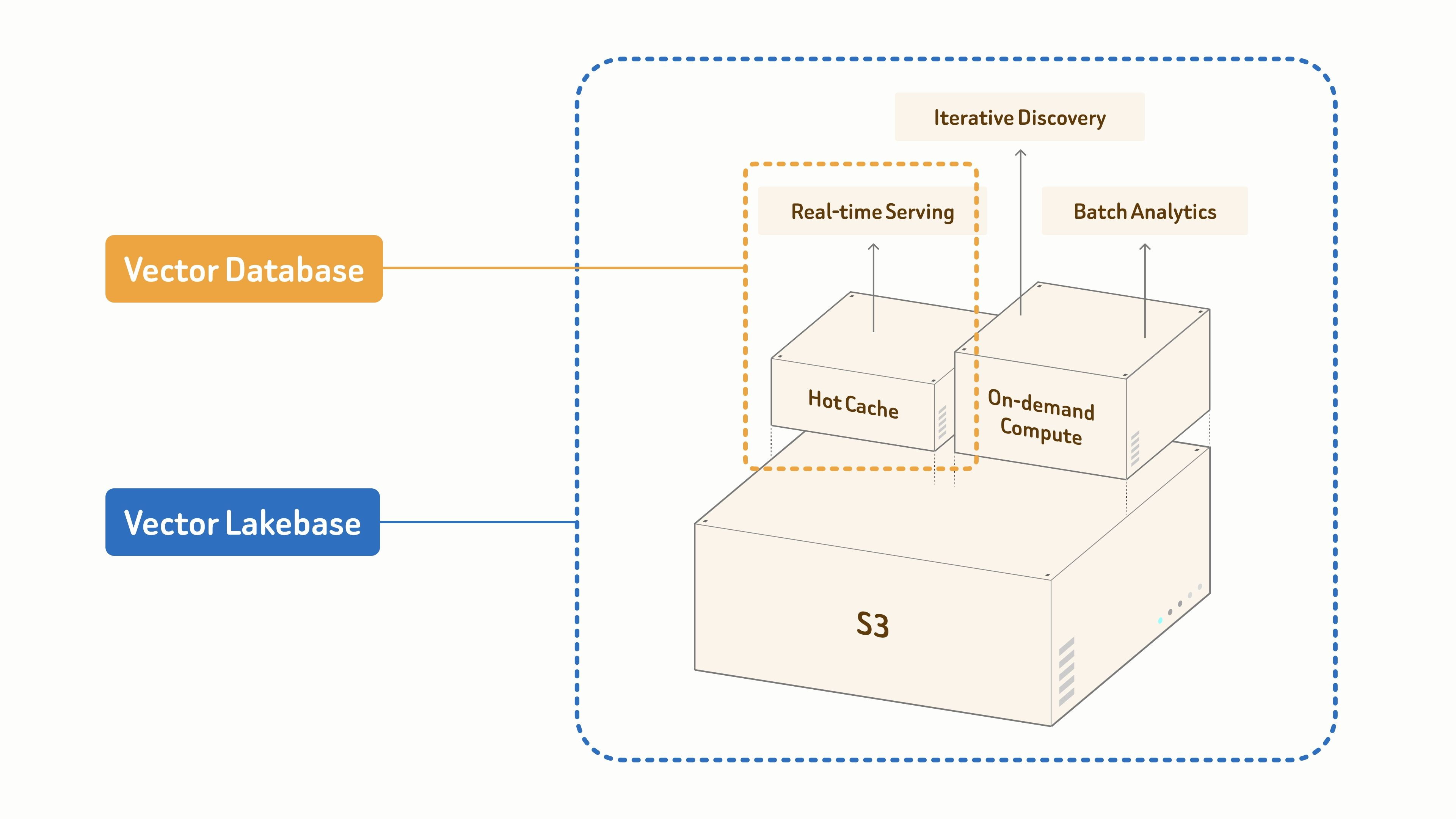
工作流概述
本演示使用三种类型的本地数据:
- CSV 文件存储每个 3D 资产的元数据,例如类别、风格、对象类型、颜色、使用场景、文件名和相关的项目信息。
- milvus_render_images/ 文件夹存储 Tripo 生成资产的渲染预览图。这些渲染图是主要的检索目标。
- milvus_input_images/ 文件夹存储在图生 3D(image-to-3D)生成过程中使用的参考图。这些图主要用作元数据和可选的查询参考。
简单来说:这种配置允许用户通过描述需求、上传视觉参考或结合两者,在资产库中查找相关资产。
前提条件
在开始之前,请确保已准备好以下内容:
- Zilliz Cloud 账号。Zilliz Cloud 是由 Milvus 团队打造的托管式向量湖仓平台。它将生产级向量数据库与多模态数据的湖原生(lake-native)基础相结合,让您无需自行运维向量基础设施即可存储嵌入向量和结构化元数据。免费层级已足够完成本教程。注册 Zilliz Cloud,创建一个免费集群,并获取其 URI 和 Token。
- OpenRouter API 密钥,用于下文使用的 Gemini 多模态嵌入模型。
- Python 3.10+,并安装了 Milvus Python SDK(
pip install -U pymilvus)。如果您是初次使用,请参考 PyMilvus 安装指南。 - 一套 Tripo 生成的 3D 资产 —— 渲染预览图,以及(可选的)用于图生 3D 的参考图。
步骤 1:准备 Tripo 生成的 3D 资产数据
第一步是准备通过 Tripo 生成的数据。
每个资产应至少包含:
- 渲染预览图
- CSV 中的元数据行
- 可选的输入/参考图信息
- 类别、风格、使用场景、对象和颜色字段(如果适用)
例如,一个资产可能包含如下元数据:
| 字段 | 示例值 |
|---|---|
| 类别 | 角色 |
| 风格 | 奇幻 |
| 对象类型 | 女战士 |
| 颜色 | 蓝色,银色 |
| 使用场景 | 游戏资产 |
| 文件名 | warrior_female_01.webp |
这些元数据非常重要,因为仅靠向量搜索并不总是足够。在实际的资产库中,用户通常希望将语义搜索与过滤器结合使用。
例如:
- 在“游戏资产”使用场景下查找“女性角色”。
- 在“武器”类别下查找“带有蓝色宝石的奇幻剑”。
- 查找特定视觉风格的资产,如写实(realistic)、卡通(cartoon)、科幻(sci-fi)或低多边形(low poly)。
元数据结构设计得越好,您的资产库就越实用。
嵌入的图像格式限制
渲染图和输入的参考图以 .webp 格式存储,以提高存储效率。
然而,Gemini 嵌入模型(gemini-embedding-2-preview)目前仅稳定支持 PNG 和 JPEG 输入。取决于 API 后端,WebP 格式的图像可能会导致嵌入失败。
因此,在生成嵌入向量之前,需要进行预处理步骤将图像转换为 PNG 或 JPEG。
步骤 2:创建 Zilliz Cloud Collection
在 Zilliz Cloud 中,Collection 中的每条记录都代表一个 Tripo 生成的 3D 资产。
这正是向量湖仓(Vector Lakebase)模式的用武之地。传统的向量数据库非常适合实时相似度搜索。而向量湖仓在保留该检索路径的同时,为多模态数据、批处理分析、迭代探索和治理添加了共享的湖原生数据基础。在本演示中,我们以轻量级的方式使用它,但随着 Tripo 资产库的扩大,该结构可以无缝扩展。
Collection 同时存储结构化元数据和多模态向量。关键的向量字段是 multimodal_vector。在本演示中,向量维度为 3072,并使用 COSINE(余弦相似度)作为相似度度量指标。
由于文本、图像以及“文本+图像”的查询都被嵌入到同一个向量空间中,系统可以使用一个统一的向量字段检索所有资产。
以下是简化的 Schema 设置:
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
接下来创建向量索引:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
定义好 Schema 和索引后,运行:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
命令执行完成后,您应该可以在 Zilliz Cloud 控制台中看到该 Collection。
点击该 Collection,您还可以查看其状态、Schema、已加载的实体(entities)以及向量字段配置。
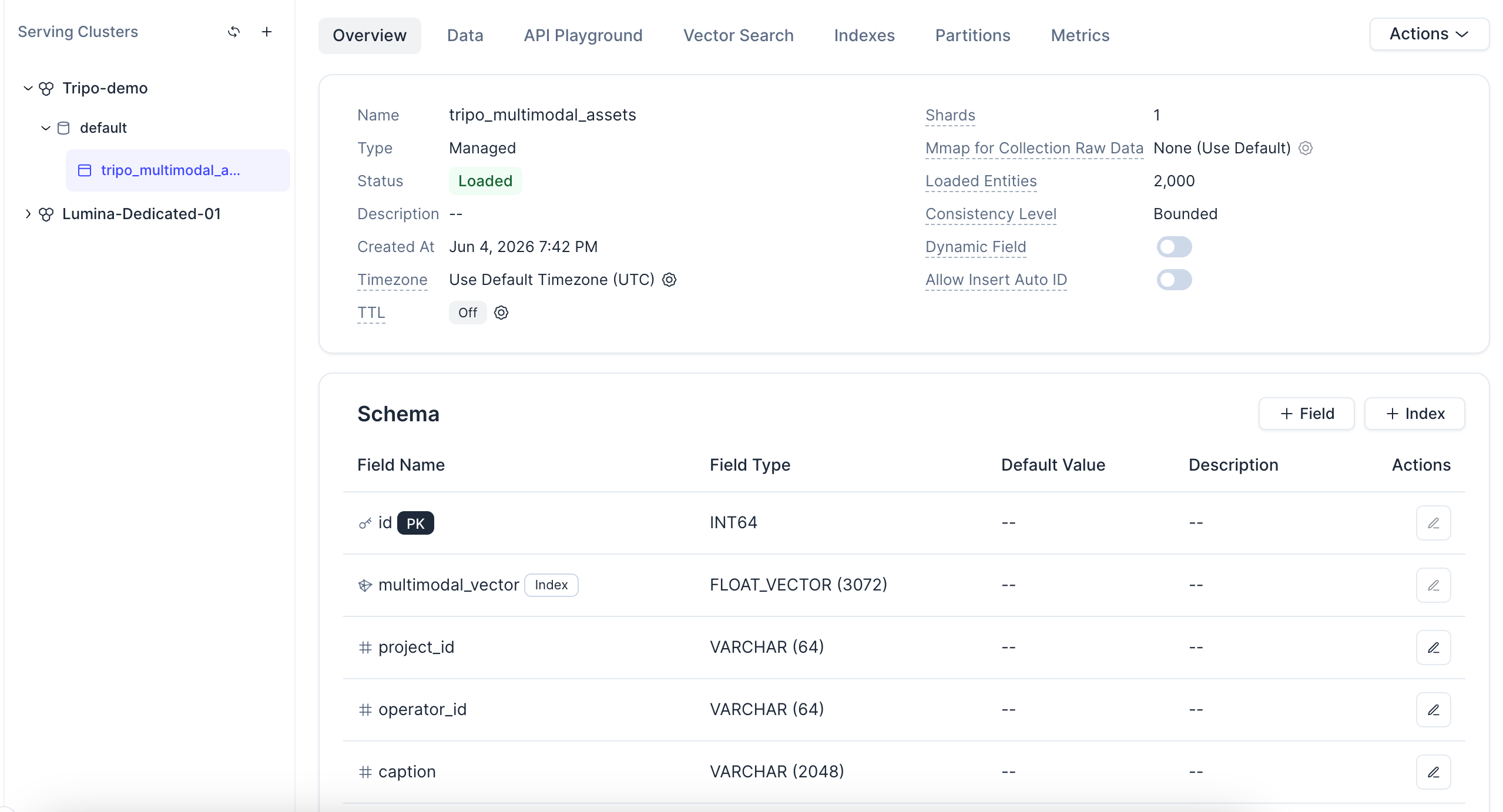
关于索引的说明:本演示使用 AUTOINDEX,它允许 Zilliz Cloud 根据您的数据自动选择和调优向量索引 —— 无需手动挑选索引类型或参数。COSINE 度量类型与下一步中生成的 L2 归一化嵌入向量相匹配。由于每条记录都是托管 Collection 中的一个实体,相同的配置可以从数百个资产扩展到数百万个,而无需重新设计架构。
步骤 3:为渲染图生成嵌入向量
接下来,为 Tripo 渲染预览图生成嵌入向量。
在该工作流中,渲染图将被转换为 base64 数据 URL 并发送到嵌入模型。返回的向量经过归一化处理,以便用于 COSINE 相似度搜索。
以下是核心逻辑:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
要为整个数据集构建嵌入缓存,请运行:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
缓存步骤非常实用,因为生成嵌入向量可能会很耗时且依赖 API。无需在每次导入数据时都重新生成嵌入,您可以一次性构建缓存,并在导入过程中重复使用。

生成嵌入缓存(embedding cache)后,CSV 中的每一行都将被转换为一个 Zilliz Cloud 实体(entity)。
每个实体包括:
- 资产 ID (Asset ID)
- 项目 ID (Project ID)
- 操作员 ID (Operator ID)
- 描述 (Caption)
- LLM 生成的元数据
- 生成模式
- 渲染图像文件信息
- 输入图像文件信息
- 多模态向量
以下是实体转换函数的简化版本:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
然后导入完整的数据集:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
导入完成后,打开 Zilliz Cloud 控制台并查看 Data 选项卡。您应该能够看到导入的资产记录,包括元数据字段和向量信息。
此时,Tripo 生成的 3D 资产不再只是本地文件。它们现在已成为向量数据库中可搜索的实体。
步骤 5:搜索 3D 资产库
该搜索系统支持三种查询模式:
- 文本搜索 — 通过语义描述进行搜索
- 图像搜索 — 通过视觉相似度进行搜索
- 文本 + 图像搜索 — 结合两者进行更精确的检索
所有这三种查询类型都会使用相同的多模态嵌入模型转换为向量。然后,在 Zilliz Cloud 中针对 multimodal_vector 字段对查询向量进行搜索。
文本搜索
当用户已经明确知道自己想要什么时,文本搜索非常有用。
查询示例:“身穿蓝色和银色盔甲的女性角色”
系统会对文本查询进行嵌入(embed),搜索集合,并返回最接近的渲染图像及其元数据。
这对于希望通过语义意图而不是准确文件名进行搜索的创意团队特别有用。例如,设计师不需要记住文件的名称是 char_f_warrior_01 还是 f_warrior_blue。他们只需搜索:“女性战士 蓝色盔甲”。这就是文件归档与真正的资产检索系统之间的区别。
图像搜索
当用户拥有参考图像并希望寻找视觉上相似的 3D 资产时,图像搜索非常有用。
例如,游戏美术设计师可以上传一个风格化盾牌的参考图像,并在现有库中搜索相似的 Tripo 生成道具。系统可以检索与上传参考的视觉结构、风格或物体概念相匹配的资产,而无需手动浏览数百张图像。
文本 + 图像搜索
文本加图像搜索是最灵活的选择。它允许用户将语义意图与视觉引导结合起来。
例如,用户可以上传一把剑的参考图像,并添加文本查询:“带有蓝色宝石的奇幻宝剑”。图像提供视觉参考,而文本则缩小了搜索意图。这使得检索比仅使用其中一种输入更为精准。
以下是简化的搜索逻辑:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
返回的结果包括相似度得分和元数据,从而可以在前端界面中显示匹配的资产预览。
请注意,搜索并不局限于纯向量相似度。因为每个资产都带有结构化元数据(类别、风格、使用场景等),您可以在单个请求中将语义相似度与元数据条件结合起来——例如,搜索“female”,但将结果限制为 llm_use_case == "game asset"。这就是过滤搜索(filtered search),它能将一堆杂乱的向量变成一个可查询的资产目录。如果您以后想同时匹配多个信号,Zilliz Cloud 还支持针对每个资产的多个嵌入进行多向量混合搜索(multi-vector hybrid search)。
示例 1:按文本和使用场景搜索
在演示中,一个示例查询使用了文本 "female",配合使用场景过滤器 llm_use_case == "game asset",并设置 limit=12。
这将检索出与“female”语义相关且属于游戏资产(game asset)使用场景的前 12 个最匹配的资产。
这种类型的搜索对于游戏开发管线非常有用,团队可以从庞大的内部库中快速定位角色概念、NPC 设计、风格化化身或类人资产。
示例 2:按文本和参考图像搜索
另一个示例将文本查询与参考图像结合起来。
文本查询为:“带有精致装饰和发光效果的奇幻风格武器”。查询中还包含了一张视觉参考图像。然后,系统为文本和图像共同生成一个联合嵌入,搜索相同的向量字段,并返回最相关的渲染图像。
当用户的意图过于具体,仅凭文本无法表达时,这非常有用。对于视觉资产搜索,“与这个相似,但更像那个”往往正是创作者的真实想法。
为什么这个工作流至关重要
这里的真正价值不仅在于图像搜索本身,而在于可复用的 AI 3D 资产基础设施。Tripo 负责快速生成;Zilliz Cloud 负责向量存储、相似度搜索、元数据检索以及多模态搜索背后的数据层。它们结合在一起,将孤立的 3D 输出转化为一个有组织、可搜索、可复用的库,这直接提高了大规模创建 3D 内容团队的生产效率。
由于 Zilliz Cloud 是专为生产环境中的 AI 构建的,这种模式可以从小规模开始,并随着团队的扩大而扩展。游戏工作室可以定位角色、道具和环境的变体;电商团队可以按类别、颜色或材质组织商品模型;营销团队可以重复使用现有的视觉效果,而无需重新生成;创意运营团队可以维护一个跨项目、集中的、可搜索的已批准资产库。
结论
AI 3D 生成现在的速度已经足够快,以至于创作不再是唯一的瓶颈。下一个挑战在于模型生成之后会发生什么——如何存储它、重新找到它、对其进行管理和复用,而不是让它消失在某个文件夹中。
此工作流连接了 Tripo 和 Zilliz Cloud,恰好解决了这个问题:Tripo 从文本或参考图像生成高质量资产,而 Zilliz Cloud 则添加了检索层——渲染图像、多模态嵌入、结构化元数据以及可扩展的向量搜索。换句话说,Tripo 成为 3D 创作引擎,而 Zilliz Cloud 则成为 AI 数据基础设施,确保这些创作可搜索、可复用,并随时可用于下一个项目。
亲自动手尝试
AI 3D 生成只是第一步——真正的回报来自于将生成的资产转化为一个结构化、可搜索的系统,并能在团队和项目之间进行扩展。通过 Tripo,您可以从文本提示词或参考图像生成高质量的 3D 资产。通过 Zilliz Cloud,您可以通过针对文本和图像的多模态向量搜索来组织和检索它们,这得益于专为生产级 AI 工作流设计的托管型 Vector Lakebase。
- 注册 Zilliz Cloud,并在免费层上完整地完成本教程。
- 使用 Tripo 生成您的 3D 资产
