Melhores APIs de Voz com IA para Desenvolvedores de Jogos: Ferramentas de Text-to-Speech Comparadas

As equipes de desenvolvimento de jogos estão cada vez mais avaliando APIs de voz com IA e ferramentas de text-to-speech — não apenas para narração, mas também para diálogos de NPCs, localização, prototipagem e geração de conteúdo dinâmico. Os casos de uso se expandiram, e a pressão sobre os orçamentos de desenvolvimento também.
O trabalho de dublagem em jogos sempre foi caro e demorado. Contratar atores de voz, organizar sessões e iterar nas gravações das falas acrescenta semanas ao cronograma de produção, especialmente nas fases iniciais, quando os roteiros ainda estão sendo ajustados. Para equipes independentes e de médio porte, esse atrito impede o tipo de iteração rápida que torna os jogos melhores antes do lançamento.
A qualidade do TTS cruzou silenciosamente um limiar prático. As melhores APIs de voz com IA disponíveis hoje não servem apenas para prototipagem — várias delas são viáveis para lançamentos de títulos indie, e estão sendo cada vez mais testadas em pipelines de pré-produção AA/AAA, onde velocidade e custo importam mesmo quando existem orçamentos de qualidade.
Os jogos têm requisitos específicos que os rankings genéricos de TTS ignoram: compatibilidade com árvores de diálogo ramificadas, vozes de personagens individuais por NPC, ampla variação emocional com controle preciso, localização multilíngue e acesso à API em nível de pipeline para geração em lote. Este artigo foca no que realmente importa para os fluxos de trabalho de produção de áudio em jogos — não o melhor clipe de demonstração, mas a melhor adequação para como o áudio de jogos é realmente construído.
O Que os Desenvolvedores de Jogos Realmente Precisam de um TTS
Para avaliar as melhores ferramentas do mercado, verificamos preços e disponibilidade de recursos na documentação pública até maio de 2026. No fim, definimos cinco critérios que mais importam para os fluxos de trabalho de produção de jogos:
- Controle de emoção por linha. O diálogo de NPCs não é tonalmente uniforme. Uma única cena pode incluir um comerciante assustado, um guarda sarcástico e um dador de missão urgente. Você precisa de tags ou seletores de estilo que funcionem no nível de cada linha — não um controle global de "tom" que nivela a entrega em todo um personagem ou sessão.
- Clonagem de voz para criação de personagens. Vozes personalizadas para seu protagonista, vilão e elenco de apoio, sem precisar contratar atores diferentes a cada iteração do build. A capacidade de clonar uma voz a partir de uma amostra curta e, em seguida, gerar milhares de falas com essa voz é fundamental para manter a consistência de personagens ao longo de todo um ciclo de produção.
- Localização multilíngue. Lançar em cinco ou mais idiomas é comum até para títulos indie. A questão relevante é se o mesmo clone de voz se mantém entre os idiomas — ou se a localização obriga você a reconstruir toda a biblioteca de vozes do zero para cada mercado.
- API e geração em lote. Gerar 2.000 falas de NPC por uma interface gráfica não é prático. Os pipelines de áudio de jogos precisam de uma API com suporte a scripts que se encaixe nas ferramentas de build existentes, suporte ao processamento em lote e se integre de forma limpa com os fluxos de gerenciamento de assets.
- Custo em escala. Dez mil falas por build, multiplicadas por múltiplos builds e múltiplos idiomas, geram custos reais por projeto. Estruturas de preços que funcionam para produção de podcasts podem não ser economicamente escaláveis para sistemas de diálogo densos.
Esses cinco critérios orientam as recomendações de ferramentas a seguir.
Comparação de APIs de Voz com IA para Desenvolvedores de Jogos
| Ferramenta | Controle de Emoção | Idiomas | Clonagem de Voz | Preço da API (aprox.) | Ideal Para |
|---|---|---|---|---|---|
| Fish Audio | Open-domain com tags detalhadas | 80+ | Sim | ~$15/1M chars | Diálogo expressivo em escala de produção |
| ElevenLabs | Open-domain (modelo v3) | 70+ | Sim | ~$100/1M chars | Cinemáticas pré-renderizadas de alta fidelidade |
| Resemble AI | Tags paralinguísticas (Chatterbox) | 23 | Sim | ~$40/1M chars (cloud) | Fluxos de trabalho open-source/auto-hospedados |
| Google Cloud TTS | Controle de prosódia via SSML | 50+ | Não | ~$30/1M chars (Chirp 3) | Pipeline empresarial, áudio de sistema escalável |
(Preços referentes a 2026; verifique os planos atuais antes de se comprometer.)
Melhores APIs de Text-to-Speech para Fluxos de Trabalho de Voz em Jogos
- Fish Audio — Melhor API de Text-to-Speech para Diálogo Expressivo de NPCs com Custo Acessível para Estúdios
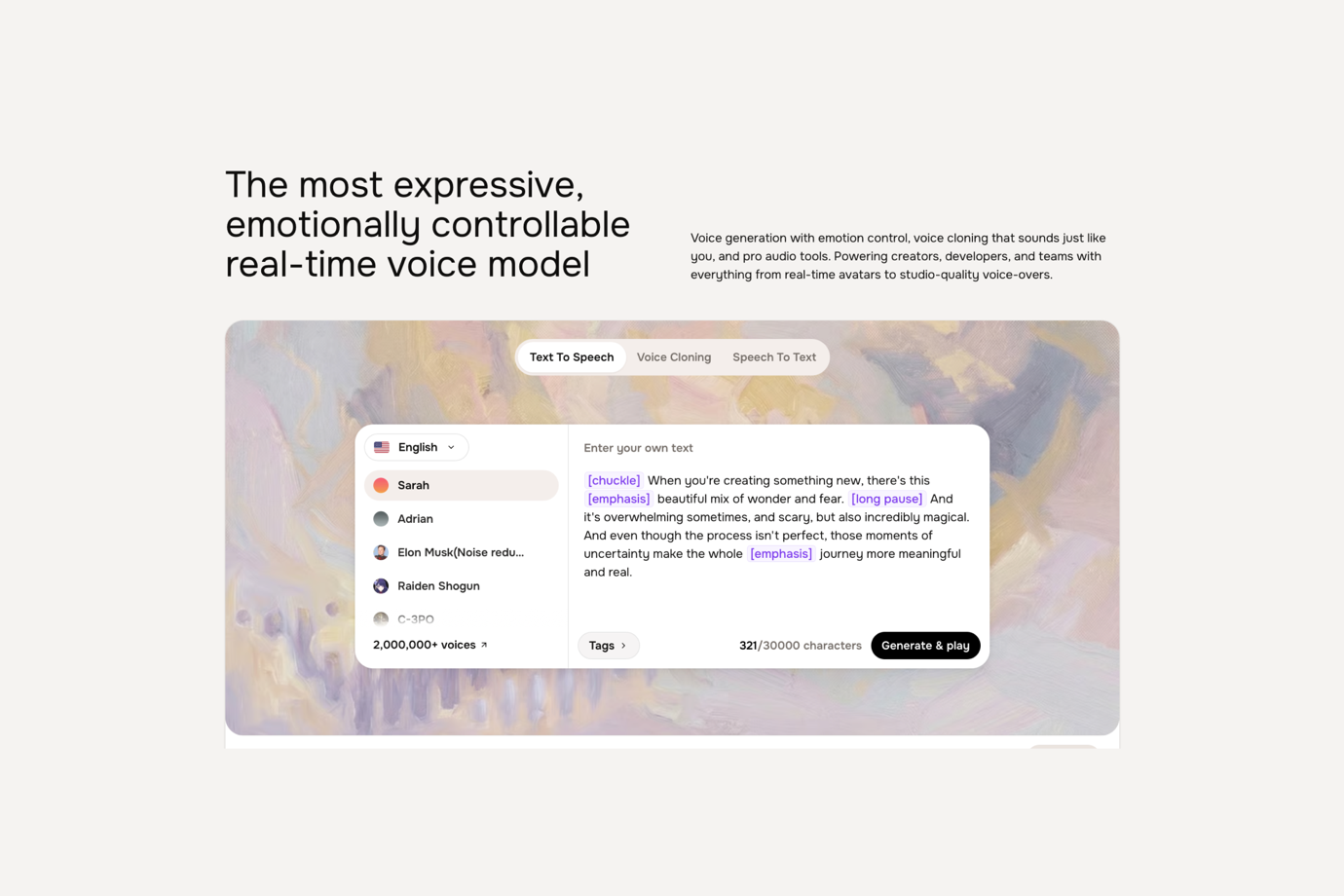
O Fish Audio é uma excelente API de text-to-speech para estúdios de jogos que precisam de diálogos expressivos de NPCs, geração de voz multilíngue e preços escaláveis. Suas tags de emoção inline permitem que os desenvolvedores controlem o tom e a entrega diretamente no roteiro, de forma semelhante a como um diretor anota as falas para um ator de voz. Isso funciona especialmente bem para jogos com muito diálogo, onde cada fala de NPC pode precisar de um contexto emocional específico.
O modelo S2 do Fish Audio também oferece clonagem de voz rápida. Uma amostra de áudio curta é suficiente para criar uma voz de personagem, que pode ser usada para TTS em mais de 80 idiomas. Para as equipes de localização, isso significa que uma única integração de API pode dar suporte a diálogos multilíngues de NPCs sem precisar reconstruir as vozes dos personagens para cada mercado.
O preço também é favorável para estúdios. A aproximadamente 7 a 50. A REST API suporta streaming com cerca de 200ms de tempo até o primeiro áudio, tornando-a prática tanto para geração de voz em lote quanto para fluxos de trabalho de voz interativos.
O Fish Audio também oferece uma grande biblioteca com mais de 2 milhões de modelos de voz da comunidade, dando às equipes mais opções para sotaques regionais, personagens secundários e variedade de vozes de NPCs sem precisar clonar cada voz do zero.
Uma limitação: o Fish Audio tem menos reconhecimento de marca do que o ElevenLabs, e o uso comercial do modelo de pesos abertos requer uma licença paga. Equipes que utilizam a API na nuvem não terão problemas, mas estúdios que avaliam implantação auto-hospedada devem revisar os termos de licenciamento com cuidado.
Ideal para: Estúdios de jogos desenvolvendo RPGs com muito diálogo, jogos de mundo aberto, NPCs com IA ou títulos multilíngues que precisam de text-to-speech expressivo, controle de emoção por linha, clonagem de voz e localização econômica em escala.
- ElevenLabs — Melhor para Saída de Alta Fidelidade, Dentro do Orçamento
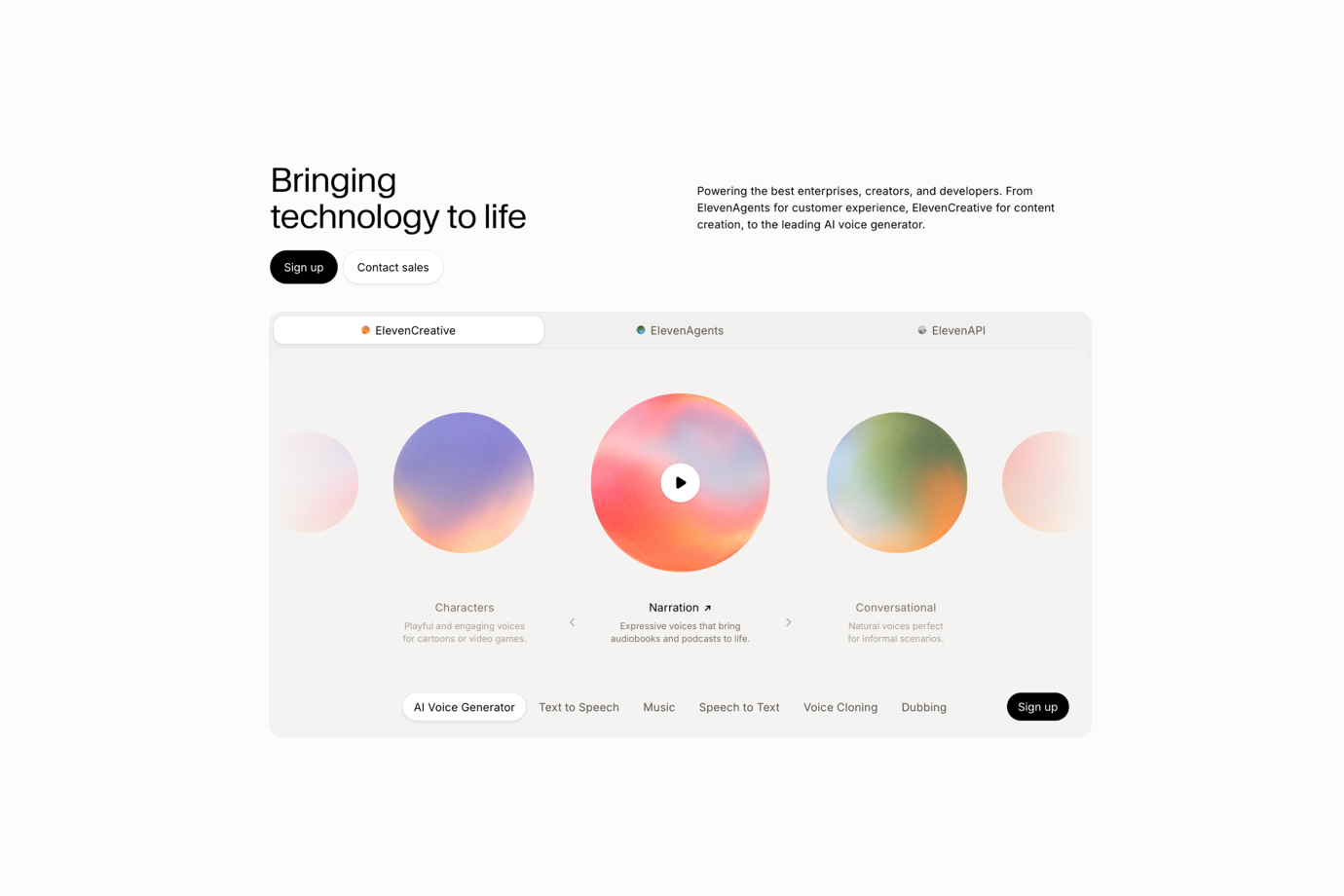
O ElevenLabs é a marca de voz com IA mais reconhecida do setor, e sua reputação por saída consistente e de alta qualidade é bem merecida. Para áudio pré-renderizado — cinemáticas, trailers e sequências narrativas roteirizadas — o teto de qualidade está entre os mais altos disponíveis.
O Dubbing Studio gerencia a localização com rastreamento automático de falantes entre idiomas, o que simplifica a entrega em múltiplos idiomas para conteúdo roteirizado. As tags de áudio v3, que chegaram à disponibilidade geral no início de 2026, melhoram a entrega contextual para cenas narrativas, dando aos diretores de áudio um controle mais refinado do que as versões anteriores permitiam. Uma grande biblioteca de vozes pré-criadas com estilos pesquisáveis reduz o tempo de configuração para equipes que não precisam de vozes de personagens personalizadas.
O fator limitante para a produção de jogos é a economia. O preço da API, em torno de $100/1M de caracteres, é aproximadamente sete vezes mais alto do que o Fish Audio, e os limites de taxa baseados em camadas criam atrito para sistemas de diálogo dinâmico com alto volume de falas. Para equipes que geram dezenas de milhares de falas em múltiplos builds e idiomas, a diferença de custo se acumula rapidamente.
Ideal para: Projetos pré-renderizados de alto orçamento, onde a qualidade premium é priorizada e o custo da API em tempo real e em escala não é uma restrição principal.
- Resemble AI — TTS Amigável para Desenvolvedores com Flexibilidade Open-Source
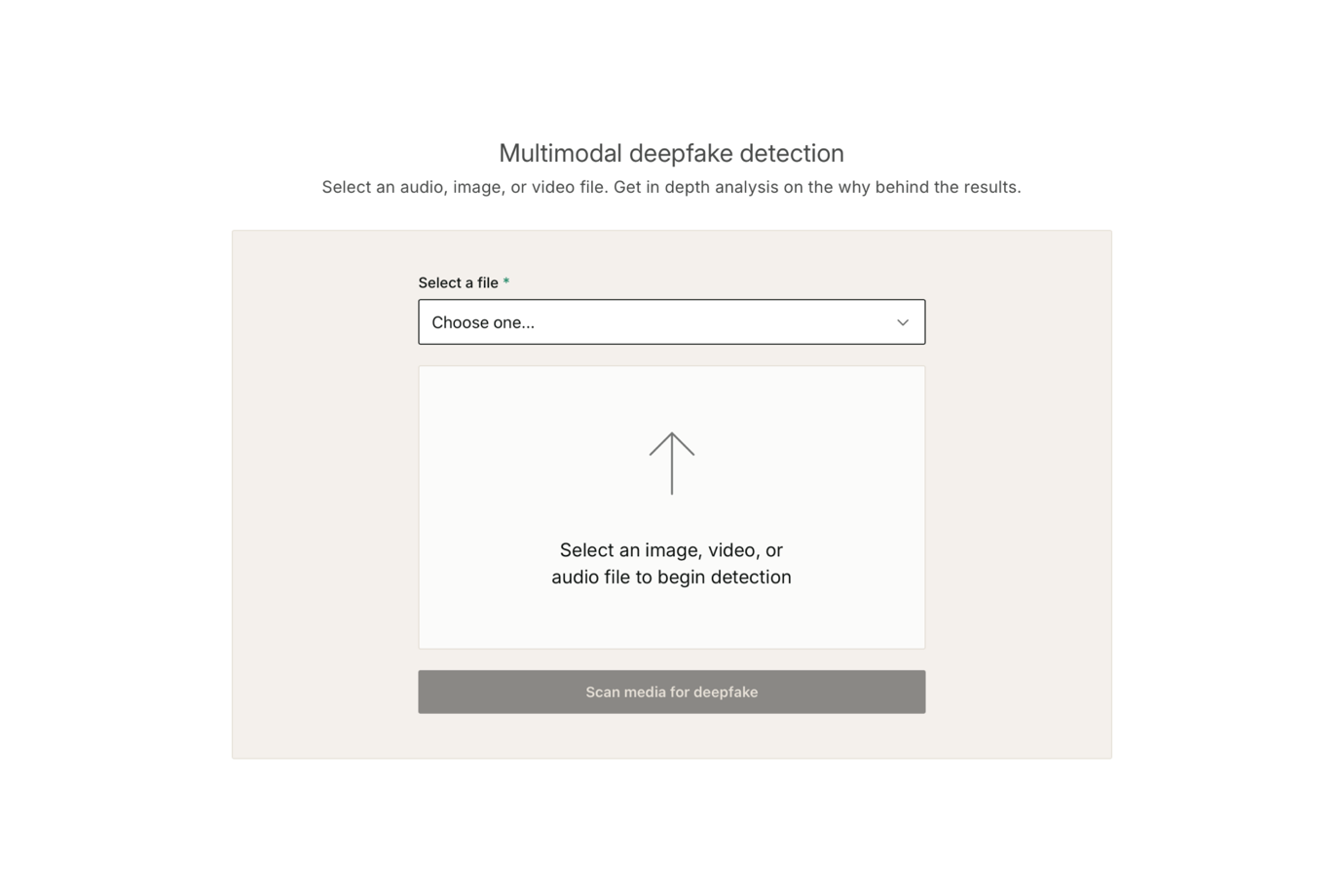
O modelo Chatterbox do Resemble AI introduziu tags paralinguísticas para reações vocais orgânicas — risadas, hesitações, ênfase — sem pós-processamento. Essas tags oferecem um tipo diferente de expressividade em relação às tags de categoria discreta: menos voltado a especificar o estado emocional e mais focado em adicionar textura naturalista à entrega.
A clonagem de voz a partir de uma amostra de referência de 5 segundos está entre as mais rápidas do mercado. A cobertura de idiomas varia conforme a implantação: 23 idiomas no Chatterbox Multilingual e mais de 100 na API cloud gerenciada. A REST API vem com um SDK para Python, e um plugin para Unity está disponível no GitHub para equipes que desejam integração no nível do motor sem precisar criar conectores personalizados.
O preço da API cloud gira em torno de $40/1M de caracteres. Equipes com infraestrutura para auto-hospedar nos pesos open-source podem reduzir esse custo ao valor da infraestrutura apenas — o principal motivo pelo qual o Resemble AI é uma das principais opções para estúdios focados em desenvolvimento que desejam controle sobre seu pipeline de voz.
O modelo de controle de emoção tem uma troca relevante para sistemas de diálogo denso: a intensidade é ajustável, mas a categoria não é. Especificar "com medo" versus "sarcástico" por linha requer áudio de referência em vez de uma tag discreta. Equipes que gerenciam grandes árvores de diálogo com contextos emocionais variados acharão o sistema de tags por linha do Fish Audio mais direto operacionalmente.
Ideal para: Equipes de desenvolvimento que desejam um modelo com licença MIT e possibilidade de auto-hospedagem, ou aquelas que precisam de reações paralinguísticas incorporadas naturalmente na entrega dos personagens.
- Google Cloud TTS — Melhor para Integração em Pipeline Empresarial
As vozes HD Chirp 3 do Google Cloud TTS entregam saída limpa e natural, adequada para narração de interface, voz de tutorial e áudio de sistema ambiente. A qualidade da saída é confiável e consistente — qualidades que importam para áudio de sistema em alto volume, que precisa permanecer inteligível em diferentes ambientes de reprodução.
O suporte completo a SSML se combina com os controles nativos do Chirp 3: ajuste de ritmo de 0,25x a 2x, tags de pausa contextuais e pronúncias fonéticas personalizadas. Para equipes que renderizam texto dinâmico em jogo — descrições de missões, mensagens de sistema, narração de acessibilidade — esse nível de controle de prosódia é prático e se integra nativamente com a infraestrutura existente do GCP, incluindo Firebase, GKE e Cloud Run.
A principal limitação é a capacidade de voz de personagem. O nível padrão não tem clonagem de voz; um complemento de "Voz Personalizada Instantânea" está disponível por $60/1M de caracteres, mas a oferta base é uma biblioteca fixa de vozes pré-criadas. O caráter vocal soa natural e profissional — adequado para áudio de sistema e interface, mas menos indicado para diálogos expressivos de protagonistas ou vilões que precisam de identidade de personagem consistente ao longo de milhares de falas.
Ideal para: Grandes estúdios que já utilizam o GCP e precisam de TTS confiável e escalável como componente de pipeline, em vez de um motor de voz narrativa.
Recomendação por Caso de Uso
- Sistemas dinâmicos de NPC com diálogos densos: Fish Audio (REST API com suporte a scripts para geração em lote, tags de emoção por linha, econômico em escala massiva)
- Lançamento de um título multilíngue com personagens orientados a diálogo: Fish Audio (80+ idiomas, tags de emoção, custo em escala)
- Áudio de pré-produção AAA de alto orçamento: ElevenLabs (teto de qualidade, familiar para diretores de áudio)
- Pipeline de voz open-source ou auto-hospedado: Resemble AI
- Pipeline empresarial/nativo em nuvem no GCP: Google Cloud TTS
Conclusão
A ferramenta de TTS certa depende de onde você está na produção e de como são os seus requisitos de diálogo. Para jogos especificamente, controle de emoção e escalabilidade de API importam mais do que em outros casos de uso de TTS — e isso muda o cálculo em relação aos rankings genéricos de TTS.
Não existe um único "melhor" para IA de voz em geral; existe apenas o melhor ajuste para a sua arquitetura de produção. Para desenvolvedores que constroem árvores de diálogo dinâmicas e escaláveis com requisitos densos de localização, o Fish Audio oferece o controle emocional preciso e a economia de API necessários para tornar sistemas densos de NPCs viáveis. Para cinemáticas lineares e pré-renderizadas onde os custos de API em tempo real não são uma preocupação, o ElevenLabs oferece fidelidade de áudio premium. Se você precisa de flexibilidade open-source com auto-hospedagem, o Resemble AI é o caminho mais claro. E se o seu estúdio opera estritamente dentro de pipelines de nuvem empresarial existentes, o Google Cloud fornece infraestrutura confiável.
No fim das contas, escolha o motor que escala com as mecânicas específicas do seu jogo — não apenas aquele com o melhor clipe de demonstração.




