Las Mejores APIs de Voz con IA para Desarrolladores de Videojuegos: Comparativa de Herramientas Text-to-Speech

Los equipos de desarrollo de videojuegos evalúan cada vez más las APIs de voz con IA y las herramientas de text-to-speech no solo para la narración, sino también para los diálogos de NPCs, la localización, la creación de prototipos y la generación de contenido dinámico. Los casos de uso se han multiplicado — y con ellos, la presión sobre los presupuestos de desarrollo.
El trabajo de voz en videojuegos ha sido tradicionalmente caro y lento. Contratar actores de doblaje, organizar sesiones y revisar las lecturas de líneas añade semanas a los calendarios de producción, especialmente en las fases tempranas cuando los guiones aún están en proceso de cambio. Para los equipos indie y de tamaño medio, esa fricción bloquea el tipo de iteración rápida que mejora los juegos antes del lanzamiento.
La calidad del TTS ha cruzado silenciosamente un umbral práctico. Las mejores APIs de voz con IA actuales no solo son útiles para prototipos — varias son viables para lanzar títulos indie, y cada vez se prueban más en los pipelines de preproducción AA/AAA donde la velocidad y el coste importan incluso cuando existen presupuestos de calidad.
Los videojuegos tienen requisitos específicos que los rankings genéricos de TTS no contemplan: compatibilidad con árboles de diálogo ramificados, voces de personaje por NPC, rango emocional detallado, localización multilingüe y acceso a la API a nivel de pipeline para la generación por lotes. Este artículo se centra en lo que realmente importa para los flujos de trabajo de producción de audio en videojuegos — no en el mejor clip de demostración, sino en el mejor ajuste para cómo se construye el audio en los juegos.
Qué Necesitan Realmente los Desarrolladores de Videojuegos del TTS
Para evaluar las mejores herramientas del mercado, verificamos los precios y la disponibilidad de funciones en la documentación pública a mayo de 2026. En definitiva, decidimos que cinco criterios son los más importantes para los flujos de trabajo de producción de videojuegos:
- Control de emoción por línea. El diálogo de los NPCs no tiene una entonación uniforme. Una sola escena puede incluir a un comerciante asustado, un guardia sarcástico y un dador de misiones urgente. Necesitas etiquetas o selectores de estilo que funcionen a nivel de línea individual — no un control deslizante de "tono" global que aplana la interpretación de todo un personaje o sesión.
- Clonación de voz para la creación de personajes. Voces personalizadas para tu protagonista, villano y personajes secundarios sin necesidad de contratar actores de doblaje distintos para cada iteración de la build. La capacidad de clonar una voz a partir de una muestra corta y luego generar miles de líneas con esa voz es fundamental para mantener la coherencia de audio del personaje a lo largo de todo el ciclo de producción.
- Localización multilingüe. Lanzar en cinco o más idiomas es habitual incluso en los lanzamientos indie. La pregunta relevante es si el mismo clon de voz se mantiene entre idiomas — o si la localización te obliga a reconstruir tu biblioteca de voces desde cero para cada territorio.
- API y generación por lotes. Generar 2.000 líneas de NPC a través de una interfaz gráfica no es práctico. Los pipelines de audio para videojuegos necesitan una API programable que encaje en las herramientas de build existentes, admita el procesamiento por lotes y se integre de forma limpia con los flujos de trabajo de gestión de assets.
- Coste a escala. Diez mil líneas por build, multiplicadas por varias builds y varios idiomas de destino, generan costes reales por proyecto. Las estructuras de precios que funcionan para la producción de podcasts pueden no escalar económicamente a sistemas de diálogo densos.
Estos cinco criterios guían las recomendaciones de herramientas a continuación.
Comparativa de APIs de Voz con IA para Desarrolladores de Videojuegos
| Herramienta | Control de Emociones | Idiomas | Clonación de Voz | Precio API (aprox.) | Ideal Para |
|---|---|---|---|---|---|
| Fish Audio | Open-domain con etiquetas detalladas | 80+ | Sí | ~$15/1M chars | Diálogos expresivos a escala de producción |
| ElevenLabs | Open-domain (modelo v3) | 70+ | Sí | ~$100/1M chars | Cinemáticas pre-renderizadas de alta fidelidad |
| Resemble AI | Etiquetas paralingüísticas (Chatterbox) | 23 | Sí | ~$40/1M chars (cloud) | Flujos de trabajo open-source/self-hosted |
| Google Cloud TTS | Control de prosodia SSML | 50+ | No | ~$30/1M chars (Chirp 3) | Pipeline empresarial, audio de sistema escalable |
(Precios a 2026; verifica los planes actuales antes de comprometerte.)
Las Mejores APIs de Text-to-Speech para Flujos de Trabajo de Voz en Videojuegos
- Fish Audio — La Mejor API de Text-to-Speech para Diálogos Expresivos de NPCs a un Coste Asequible para Estudios
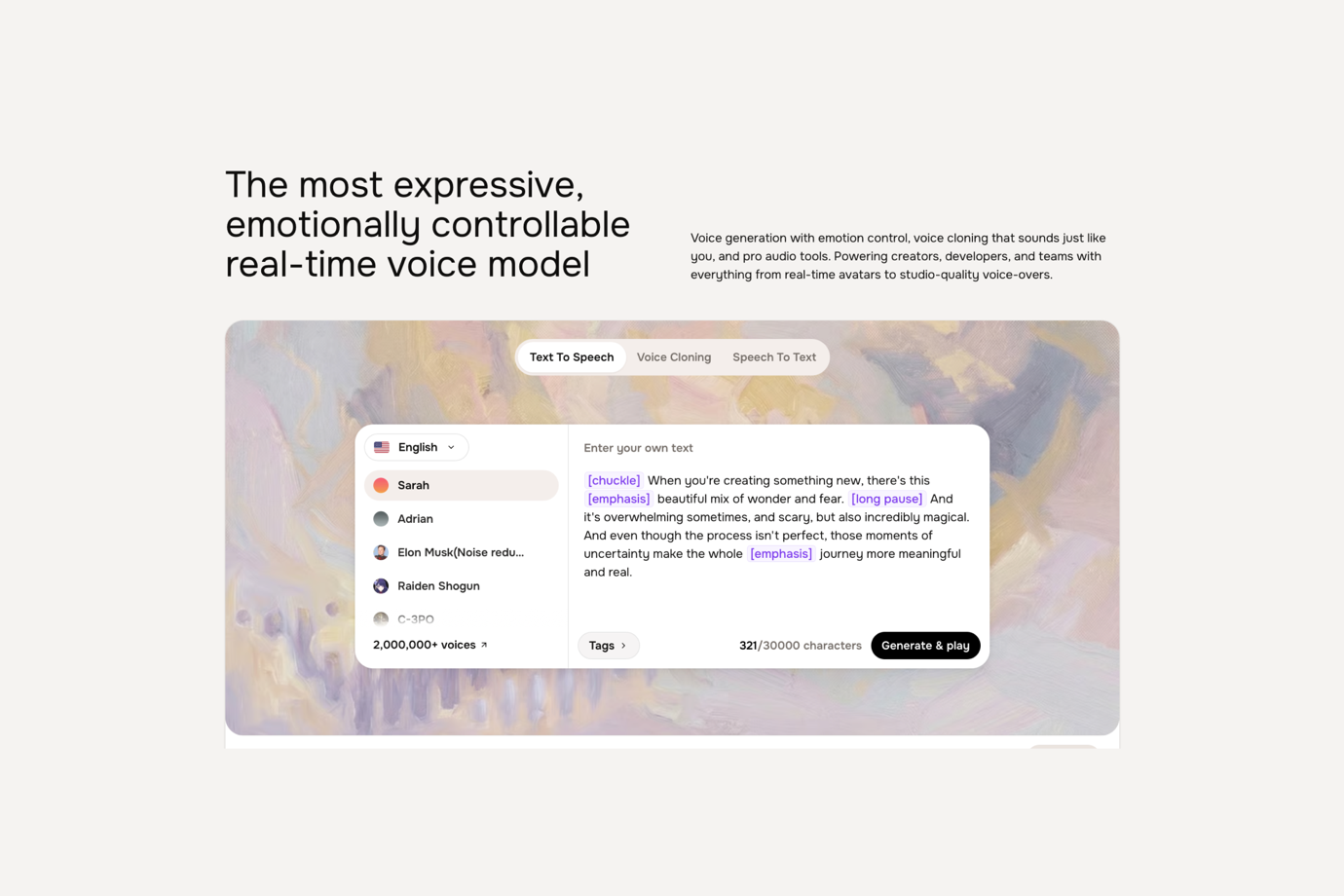
Fish Audio es una sólida API de text-to-speech para estudios de videojuegos que necesitan diálogos expresivos de NPCs, generación de voz multilingüe y precios escalables. Sus etiquetas de emoción en línea permiten a los desarrolladores controlar el tono y la interpretación directamente dentro del guion, de forma similar a cómo un director anota las líneas para un actor de doblaje. Esto funciona especialmente bien en juegos con mucho diálogo, donde cada línea de NPC puede necesitar un contexto emocional específico.
El modelo S2 de Fish Audio también admite clonación de voz rápida. Una muestra de audio corta puede crear una voz de personaje, que luego puede usarse para TTS en más de 80 idiomas. Para los equipos de localización, esto significa que una sola integración de API puede soportar diálogos de NPCs multilingües sin necesidad de reconstruir las voces de los personajes para cada mercado de destino.
Los precios también son amigables para los estudios. A aproximadamente 7--10 en generación, mientras que localizar los mismos diálogos en cinco idiomas puede mantenerse por debajo de $50. La API REST admite streaming con aproximadamente 200ms de tiempo hasta el primer audio, lo que la hace práctica tanto para la generación de voz por lotes como para flujos de trabajo de voz interactivos.
Fish Audio también ofrece una amplia biblioteca de más de 2M de modelos de voz de la comunidad, lo que brinda a los equipos más opciones para acentos regionales, personajes secundarios y variedad de voces de NPCs sin necesidad de clonar cada voz desde cero.
Una limitación: Fish Audio tiene menos reconocimiento de marca que ElevenLabs, y el uso comercial del modelo de pesos abiertos requiere una licencia de pago. Los equipos que usen la API en la nube no tendrán problemas, pero los estudios que evalúen el despliegue self-hosted deben revisar cuidadosamente los términos de la licencia.
Ideal para: Estudios de videojuegos que desarrollan RPGs con mucho diálogo, juegos de mundo abierto, NPCs con IA o títulos multilingües que necesitan text-to-speech expresivo, control de emoción por línea, clonación de voz y localización rentable a gran escala.
- ElevenLabs — La Mejor Opción para Resultados de Alta Fidelidad, si el Presupuesto lo Permite
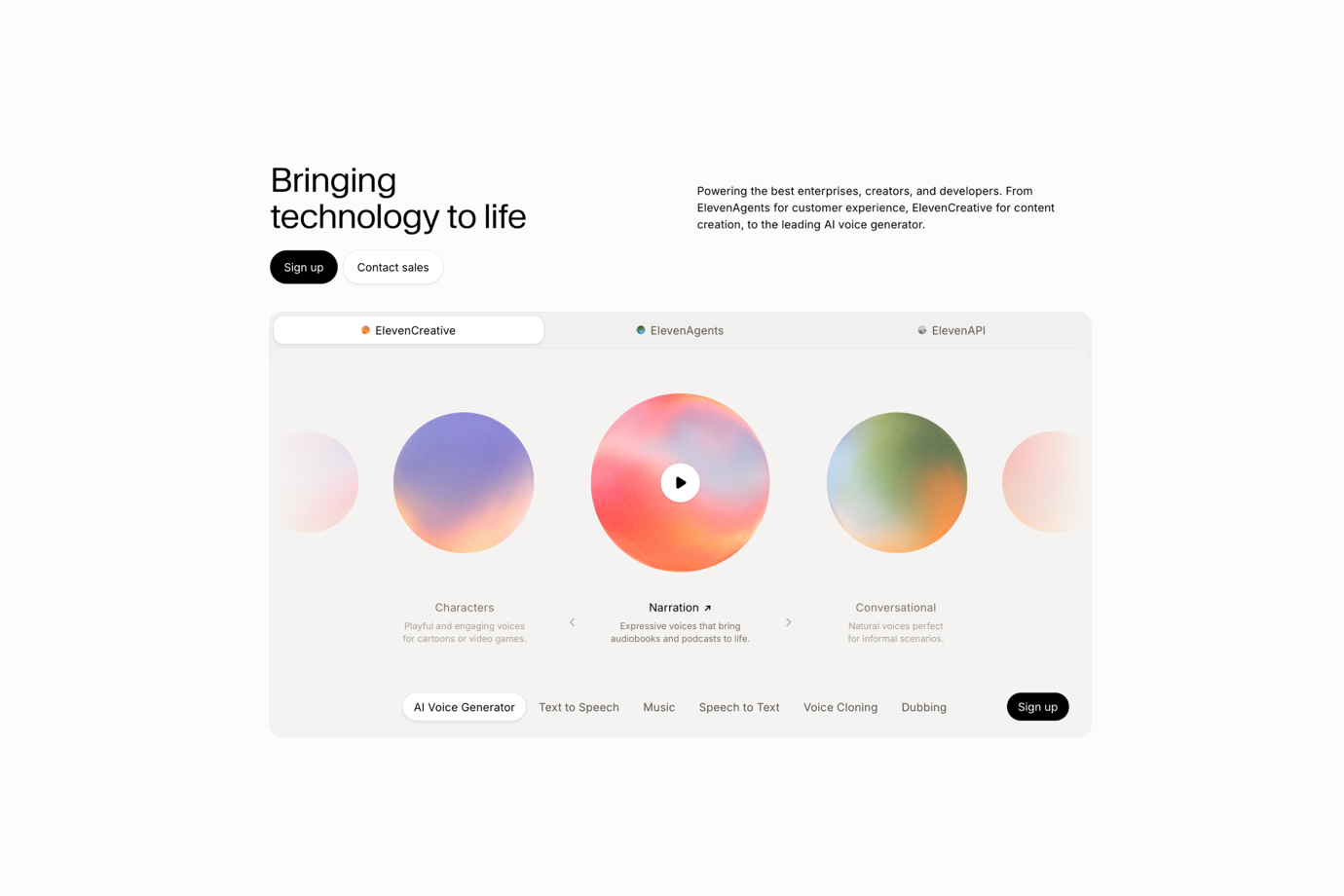
ElevenLabs es la marca de voz con IA más reconocida del sector, y su reputación por un resultado consistente y de alta calidad está bien ganada. Para audio pre-renderizado — cinemáticas, tráilers y secuencias narrativas con guion — el techo de calidad se encuentra entre los más altos disponibles.
Dubbing Studio gestiona la localización con seguimiento automático de hablantes entre idiomas, lo que simplifica la entrega en múltiples idiomas para contenido con guion. Las etiquetas de audio v3, que alcanzaron disponibilidad general a principios de 2026, mejoran la interpretación contextual para escenas narrativas, dando a los directores de audio un control más detallado que el que permitían las versiones anteriores. Una amplia biblioteca de voces predefinidas con estilos buscables reduce el tiempo de configuración para equipos que no necesitan voces de personaje personalizadas.
El factor limitante para la producción de videojuegos es la economía. El precio de la API de aproximadamente $100/1M de caracteres es aproximadamente siete veces más alto que Fish Audio, y los límites de velocidad por niveles generan fricción en sistemas de diálogo dinámico con un alto número de líneas. Para equipos que generan decenas de miles de líneas en múltiples builds e idiomas, la diferencia de coste se acumula rápidamente.
Ideal para: Proyectos pre-renderizados de alto presupuesto donde se prioriza la calidad premium y el coste de la API en tiempo real a escala no es una restricción principal.
- Resemble AI — TTS Orientado al Desarrollador con Flexibilidad Open-Source
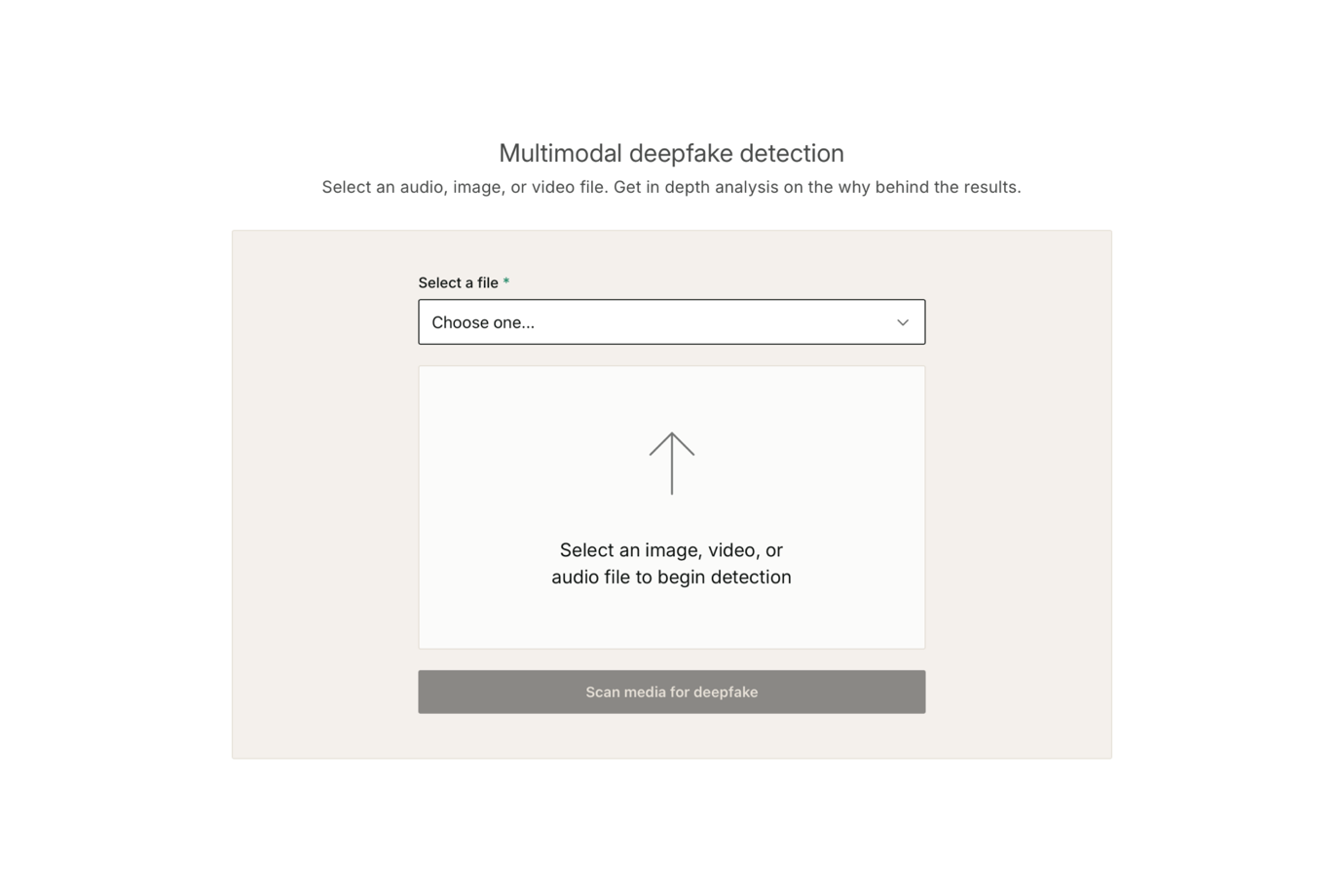
El modelo Chatterbox de Resemble AI introdujo etiquetas paralingüísticas para reacciones vocales orgánicas — risas, dudas, énfasis — sin postprocesamiento. Estas ofrecen un tipo de expresividad diferente a las etiquetas de categoría discreta: menos centradas en especificar el estado emocional, y más en añadir textura naturalista a la interpretación.
La clonación de voz a partir de una muestra de referencia de 5 segundos se encuentra entre las más breves del mercado. La cobertura de idiomas varía según el despliegue: 23 idiomas en Chatterbox Multilingual y más de 100 en la API cloud gestionada. La API REST incluye un SDK de Python, y hay un plugin de Unity disponible en GitHub para equipos que quieran integración a nivel de motor sin necesidad de construir conectores personalizados.
El precio de la API cloud ronda los $40/1M de caracteres. Los equipos con la infraestructura necesaria para hacer self-hosting con pesos open-source pueden reducirlo al coste de infraestructura únicamente — la razón principal por la que Resemble AI es una opción destacada para estudios centrados en el desarrollo que quieren control sobre su pipeline de voz.
El modelo de control de emociones tiene una desventaja notable para sistemas de diálogo densos: la intensidad es ajustable, pero la categoría no. Especificar "con miedo" frente a "sarcástico" en cada línea requiere audio de referencia en lugar de una etiqueta discreta. Los equipos que gestionan grandes árboles de diálogo con contextos emocionales variados encontrarán el sistema de etiquetas por línea de Fish Audio más directo desde el punto de vista operativo.
Ideal para: Equipos de desarrollo que desean un modelo con licencia MIT y posibilidad de self-hosting, o aquellos que necesitan reacciones paralingüísticas integradas de forma natural en la interpretación del personaje.
- Google Cloud TTS — La Mejor Opción para la Integración en Pipelines Empresariales
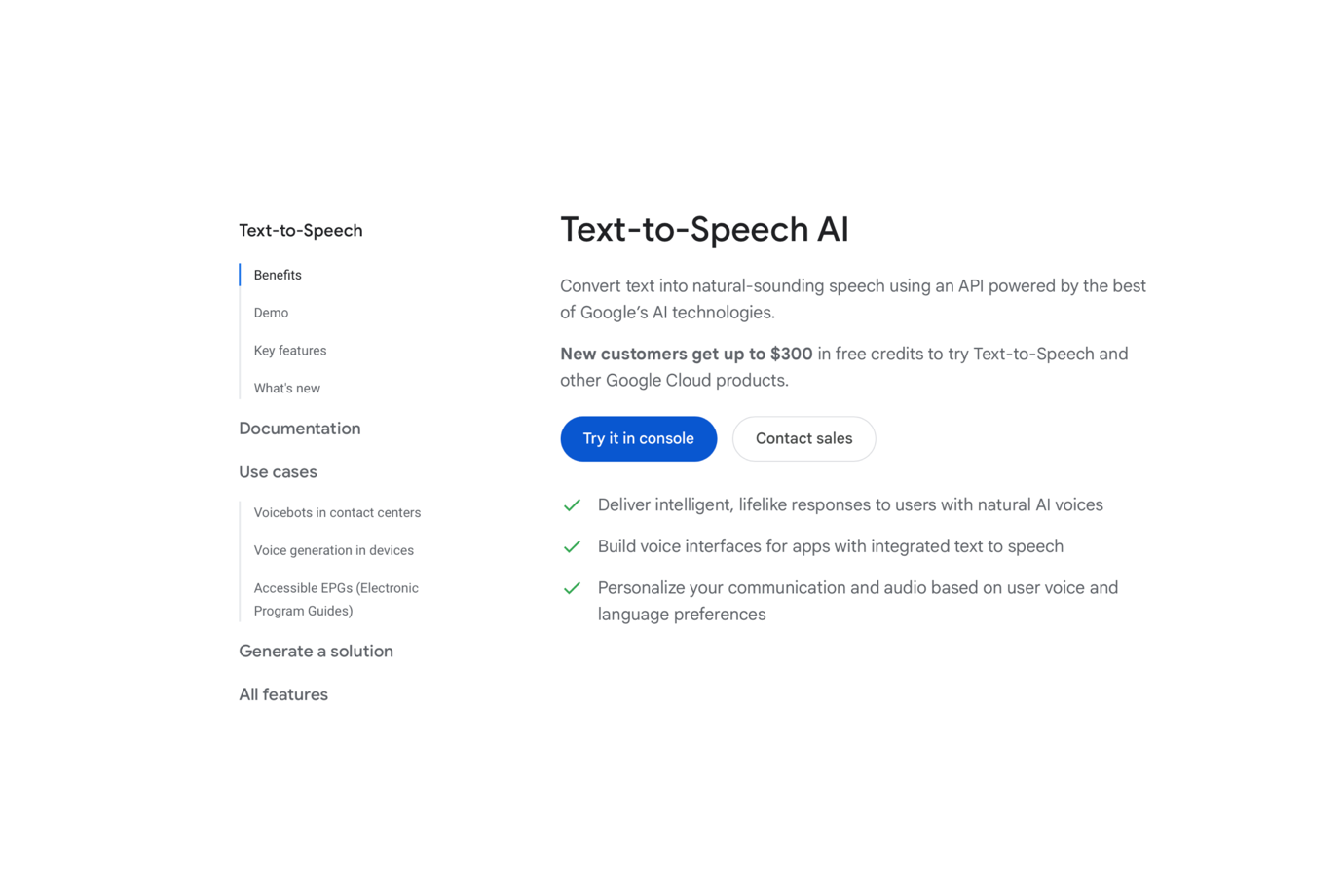
Las voces HD Chirp 3 de Google Cloud TTS ofrecen un resultado limpio y de sonido natural, adecuado para la narración de la interfaz de usuario, la voz de los tutoriales y el audio ambiental del sistema. La calidad del resultado es fiable y consistente — cualidades que importan para el audio de sistema en grandes volúmenes que necesita permanecer inteligible en entornos de reproducción variados.
El soporte completo de SSML se combina con los controles nativos de Chirp 3: ajuste de velocidad de 0,25x a 2x, etiquetas de pausa contextual y pronunciaciones de fonemas personalizadas. Para equipos que renderizan texto dinámico en el juego — descripciones de misiones, mensajes del sistema, narración de accesibilidad — este nivel de control de prosodia es práctico y se integra de forma nativa con la infraestructura de GCP existente, incluyendo Firebase, GKE y Cloud Run.
La principal limitación es la capacidad de voz de personaje. El nivel estándar no tiene clonación de voz; hay un complemento de "Instant Custom Voice" disponible a $60/1M de caracteres, pero la oferta base es una biblioteca fija de voces predefinidas. El carácter de la voz resulta natural y profesional — adecuado para el audio del sistema y la interfaz de usuario, pero menos indicado para diálogos expresivos de protagonistas o villanos que necesitan una identidad de personaje consistente a lo largo de miles de líneas.
Ideal para: Grandes estudios que ya trabajan con GCP y necesitan un TTS fiable y escalable como componente de pipeline, más que como motor de voz narrativa.
Recomendación por Caso de Uso
- Sistemas dinámicos de NPCs con diálogos densos: Fish Audio (API REST programable para generación por lotes, etiquetas de emoción por línea, rentable a gran escala)
- Lanzar un título multilingüe con personajes impulsados por diálogo: Fish Audio (80+ idiomas, etiquetas de emoción, coste a escala)
- Audio de preproducción AAA de alto presupuesto: ElevenLabs (techo de calidad, familiar para los directores de audio)
- Pipeline de voz open-source o self-hosted: Resemble AI
- Pipeline empresarial/cloud-native en GCP: Google Cloud TTS
Conclusión
La herramienta TTS adecuada depende de en qué punto de la producción te encuentres y de cómo son realmente las necesidades de tu diálogo. Para los videojuegos en particular, el control de emociones y la escalabilidad de la API importan más que en otros casos de uso de TTS — y eso desplaza el cálculo lejos de los rankings genéricos de TTS.
No existe una única voz con IA "mejor" en términos absolutos; solo existe la que mejor se adapta a tu arquitectura de producción. Para los desarrolladores que crean árboles de diálogo escalables y dinámicos con requisitos de localización densos, Fish Audio ofrece el control emocional preciso y la economía de API necesarios para hacer viables los sistemas densos de NPCs. Para cinemáticas lineales pre-renderizadas donde los costes de la API en tiempo real no son una preocupación, ElevenLabs ofrece una fidelidad de audio premium. Si necesitas flexibilidad open-source con self-hosting, Resemble AI es el camino evidente. Y si tu estudio opera estrictamente dentro de los pipelines de nube empresarial existentes, Google Cloud proporciona una infraestructura fiable.
En definitiva, elige el motor que escale con las mecánicas específicas de tu juego, no solo el que tenga el mejor clip de demostración.




