CVPR 2025|Tripo AI y la Universidad de Beihang presentan MIDI de código abierto: Generación de escenas 3D compositivas a partir de una sola imagen

Este trabajo está dirigido por investigadores de VAST, la Universidad de Beihang, la Universidad de Tsinghua y la Universidad de Hong Kong. El primer autor es Zehuan Huang, estudiante de maestría en la Universidad de Beihang, cuya investigación se centra en la IA generativa y la visión 3D. Los autores correspondientes son Yanpei Cao, Científico Jefe de VAST, y Lv Sheng, Profesor Asociado de la Universidad de Beihang.
Con Sora encendiendo una revolución en los modelos de mundo, las escenas 3D, como base digital del mundo físico, se están convirtiendo en infraestructura crítica para construir sistemas de IA dinámicos e interactivos. Los avances actuales en la generación de activos 3D a partir de imágenes únicas han proporcionado la capacidad atómica de "de la imaginación al 3D" para la creación de contenido 3D.
Sin embargo, a medida que la tecnología evoluciona hacia la generación de escenas compuestas, las limitaciones de los paradigmas de generación de objetos únicos se hacen evidentes. Los métodos existentes generan activos 3D como "átomos digitales" dispersos, luchando por autoorganizarse en "estructuras moleculares" con relaciones espaciales razonables. Esto conduce a varios desafíos centrales: ① Dilema de separación de instancias (cómo desacoplar con precisión objetos superpuestos desde una sola vista); ② Modelado de restricciones físicas (cómo evitar intersecciones y colisiones poco realistas); ③ Comprensión semántica a nivel de escena (cómo mantener la coherencia entre la función del objeto y el diseño espacial). Estos cuellos de botella obstaculizan gravemente la construcción eficiente de "mundos interactivos" a partir de "átomos digitales".
Recientemente, un equipo de investigación de la Universidad de Beihang, VAST y otras instituciones introdujo un modelo novedoso, MIDI, que puede generar escenas compuestas 3D de alta calidad geométrica y separables por instancias a partir de imágenes únicas, logrando un avance en la generación de escenas 3D de una sola vista y sentando las bases para la generación de mundos interactivos.

- Artículo: https://arxiv.org/abs/2412.03558
- Página del proyecto: https://huanngzh.github.io/MIDI-Page/
- Código: https://github.com/VAST-AI-Research/MIDI-3D
- Demostración en línea: https://huggingface.co/spaces/VAST-AI/MIDI-3D
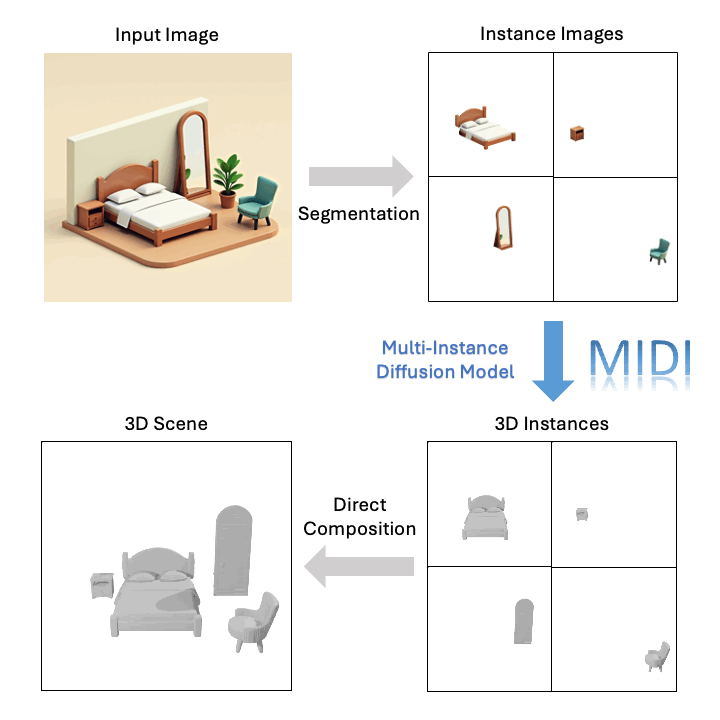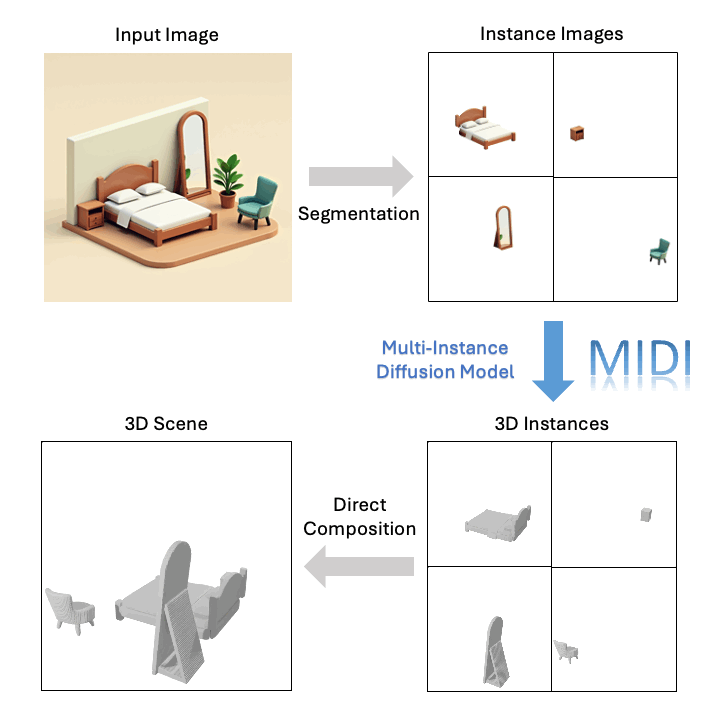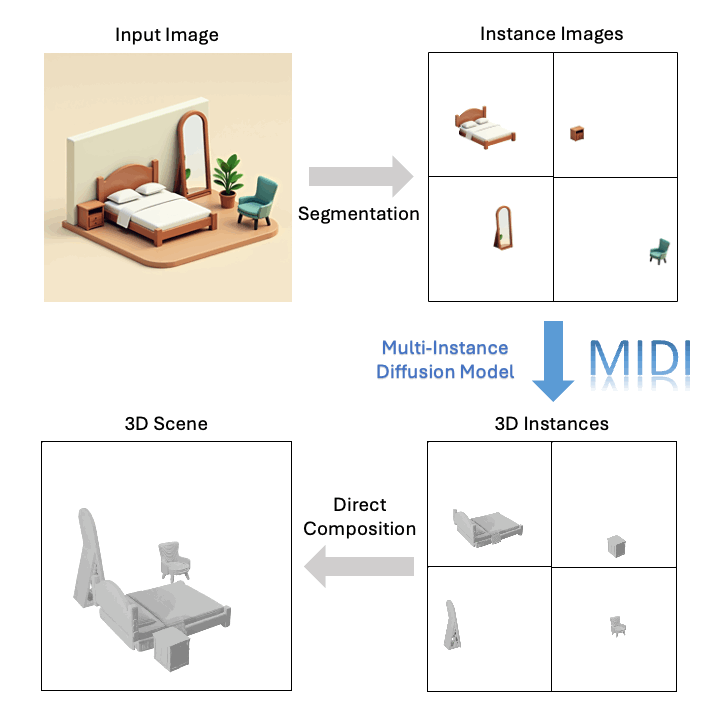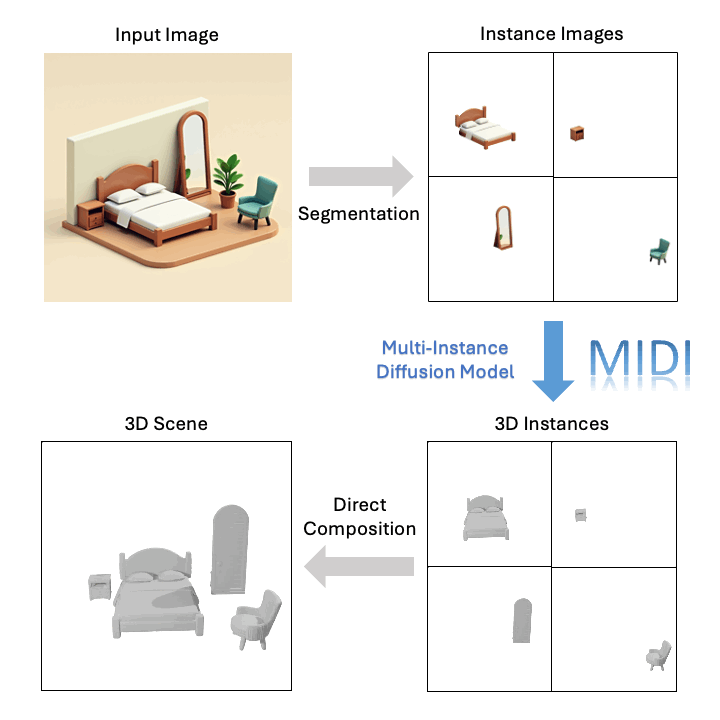
Avance Tecnológico
Las técnicas tradicionales de reconstrucción de escenas 3D compositivas a menudo se basan en la generación objeto por objeto y la optimización de escenas en múltiples etapas, lo que resulta en procesos largos y, a menudo, genera escenas con baja calidad geométrica y diseños espaciales imprecisos. Para abordar estos problemas, MIDI (Multi-Instance Diffusion Model) aprovecha de forma innovadora los modelos de generación de objetos 3D, extendiéndolos a un modelo de difusión de múltiples instancias capaz de generar simultáneamente múltiples instancias 3D con relaciones espaciales precisas, logrando una generación de escenas 3D eficiente y de alta calidad:
- De la generación de objetos individuales a la de múltiples instancias: Al denoising simultáneamente las representaciones latentes de múltiples instancias 3D e introduciendo interacciones entre tokens de múltiples instancias durante el proceso de denoising, MIDI extiende los modelos de generación de objetos 3D para generar simultáneamente múltiples instancias con modelado de interacción, que luego se combinan directamente en una escena 3D.
- Mecanismo de autoatención de múltiples instancias: Al extender el mecanismo de autoatención de los modelos de generación de objetos a la autoatención de múltiples instancias, MIDI captura eficazmente las correlaciones espaciales entre instancias y la coherencia de la escena general durante el proceso de generación, eliminando la necesidad de optimización por escena.
- Aumento de datos durante el entrenamiento: Al supervisar la interacción entre instancias 3D utilizando datos de escena limitados y al mismo tiempo aumentar el entrenamiento con datos de objetos, MIDI modela eficazmente los diseños de escenas mientras mantiene las capacidades de generalización del preentrenamiento.
Resultados Generados
Basado en una sola imagen, MIDI puede generar escenas 3D compositivas de alta calidad:




Demostración en Línea
Rendimiento Superior
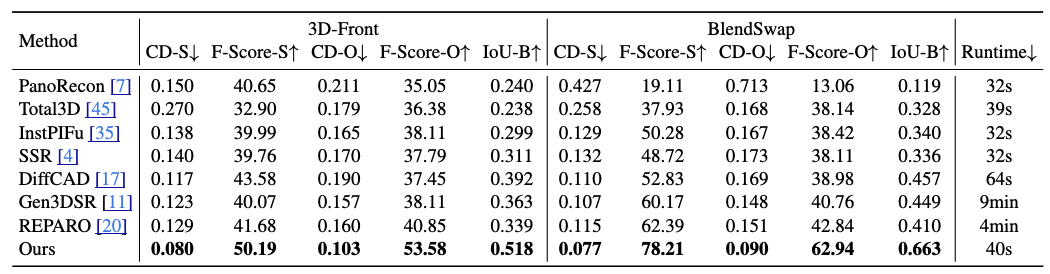
MIDI se caracteriza por su preciso modelado de diseño espacial, calidad superior de generación geométrica, eficiencia de generación y amplia aplicabilidad. Los resultados experimentales demuestran que el modelo supera a los métodos existentes en múltiples conjuntos de datos, logrando un rendimiento excelente en las relaciones espaciales de instancias 3D, la calidad geométrica de instancias 3D y la velocidad de generación de extremo a extremo.
Aplicaciones: Una Nueva Herramienta para la Creación de Contenido de Escenas 3D
MIDI proporciona una solución novedosa para la creación de escenas 3D. Esta tecnología muestra un gran potencial en varios campos como el diseño arquitectónico, la realidad virtual, los efectos especiales de cine y el desarrollo de juegos. Con sus capacidades de generación de escenas 3D de alta precisión y alta calidad geométrica, MIDI puede satisfacer la demanda de contenido de alta calidad en escenas complejas, ofreciendo a los creadores más posibilidades.
Tripo: Generador de Modelos 3D Impulsado por IA
Mientras MIDI revoluciona la composición de escenas 3D, Tripo mejora la creación de activos individuales con capacidades de IA de vanguardia:
De Imagen Única a Modelo 3D
- Convierte una sola imagen 2D en un modelo 3D de alta calidad al instante.
- La reconstrucción impulsada por IA garantiza una forma y textura precisas.
- Ideal para prototipos rápidos y visualización de conceptos.

De Múltiples Imágenes a Modelo 3D
- Utiliza múltiples imágenes desde diferentes ángulos para una mejor profundidad y detalle.
- Mejora la precisión geométrica y el realismo.
- Perfecto para el modelado preciso de objetos y el diseño de productos.

De Texto a Modelo 3D
- Genera modelos 3D a partir de descripciones de texto simples.
- La IA interpreta las indicaciones para crear activos detallados y creativos.
- Acelera la generación de conceptos para juegos, VR y animación.

Rigging y Animación Automáticos
- Riggea modelos al instante para animación con un esfuerzo mínimo.
- Estructura ósea y generación de movimiento impulsadas por IA.
- Prepara los modelos para juegos para una integración perfecta.

Trabajo Futuro
A pesar del excelente rendimiento del modelo, el equipo de desarrollo de MIDI reconoce que todavía hay muchas áreas de mejora y exploración. Por ejemplo, optimizar aún más la adaptabilidad a escenas interactivas complejas y mejorar el detalle de la generación de objetos son los enfoques clave para futuros esfuerzos. El equipo espera que, a través de la mejora y el refinamiento continuos, esta dirección de investigación no solo impulse el avance de la tecnología de generación de escenas 3D compuestas de una sola vista, sino que también contribuya a la adopción generalizada de la tecnología 3D en aplicaciones prácticas.




