Создание библиотеки 3D-ассетов с возможностью поиска на базе Tripo и Zilliz
Генерация 3D-моделей с помощью ИИ значительно упрощает создание 3D-ассетов в больших масштабах. Используя Tripo, авторы могут создавать высококачественные 3D-модели на основе текстовых промптов или референсных изображений, что крайне полезно для разработки игр, визуализации в сфере электронной коммерции, создания маркетинговых материалов, концепт-дизайна и внутренних творческих процессов.
Однако по мере роста количества сгенерированных ассетов возникает новая проблема.
Как быстро найти нужный 3D-ассет?
Когда у команды всего несколько моделей, может хватать обычных папок и ручного поиска. Но когда количество сгенерированных ассетов исчисляется сотнями или тысячами, традиционный подход к управлению файлами перестает работать. Дизайнеры могут повторно генерировать похожие модели. Разработчики игр могут терять из виду полезные вариации персонажей или пропсов. Маркетинговые команды могут тратить на поиск материалов больше времени, чем на их использование.
Именно здесь на помощь приходит библиотека 3D-ассетов на базе ИИ с возможностью быстрого поиска.
В данном рабочем процессе Tripo генерирует 3D-ассеты, а Zilliz Cloud выступает в качестве поискового слоя для мультимодальных векторов и метаданных. Платформа хранит эмбеддинги, представляющие каждое отрендеренное изображение, и связывает их с полезными полями, такими как категория, стиль, цвет, тип объекта, сценарий использования и исходный файл. В результате получается легковесная система мультимодального поиска, где пользователи могут искать по тексту, референсному изображению или обоим параметрам сразу, получая в ответ подходящие рендеры, сгенерированные в Tripo, вместе со структурированными метаданными.
Zilliz — это компания, специализирующаяся на инфраструктуре данных для ИИ, и создатель Milvus, векторной базы данных с открытым исходным кодом, на которой построен этот рабочий процесс. Milvus разработан для промышленного применения ИИ, включая такие сценарии, как RAG, ИИ-агенты, мультимодальный поиск, рекомендательные системы, корпоративные базы знаний, семантический поиск и дедупликация контента. Проект также является выпускником фонда Linux Foundation AI & Data, имеет более 44 000 звезд на GitHub и свыше 100 миллионов скачиваний на Docker Hub, предлагая командам надежную основу для хранения и поиска векторных эмбеддингов неструктурированных данных.
Это важно для пользователей Tripo, поскольку каждый 3D-ассет представляет собой нечто большее, чем просто отдельный файл. Каждую модель можно связать с превью рендера, исходным референсным изображением, описанием, тегами, категориями, цветами, сценариями использования, идентификаторами проектов и URL-адресами. Zilliz Cloud позволяет выполнять совместный поиск по всем этим параметрам, превращая растущую библиотеку сгенерированных ИИ моделей в многократно используемую систему продакшн-ассетов, а не просто в хранилище разовых результатов.
Зачем создавать библиотеку 3D-ассетов с возможностью поиска
Инструменты генерации 3D на базе ИИ обеспечивают невероятную скорость работы. Теперь один автор может за короткое время создать множество концептов персонажей, макетов продуктов, пропсов, элементов окружения или стилизованных ассетов.
Однако высокая скорость приводит к росту объемов. А большие объемы создают проблемы с управлением.
Библиотека 3D-ассетов с возможностью поиска помогает решить ряд распространенных проблем:
- Команды могут быстро находить существующие ассеты вместо создания дубликатов.
- Дизайнеры могут искать по концепции, стилю, цвету, типу объекта или сценарию использования.
- Разработчики могут более эффективно повторно использовать 3D-ассеты в разных проектах.
- Творческие команды могут создавать внутреннюю библиотеку одобренных визуальных материалов для повторного использования.
- Команды электронной коммерции или маркетинга могут упорядочивать трехмерные модели продуктов по категориям и стилям.
Вместо того чтобы относиться к сгенерированным ИИ 3D-файлам как к разовым результатам, этот рабочий процесс превращает их в систему активов многократного использования.
Почему Zilliz Cloud подходит для мультимодального поиска 3D-ассетов
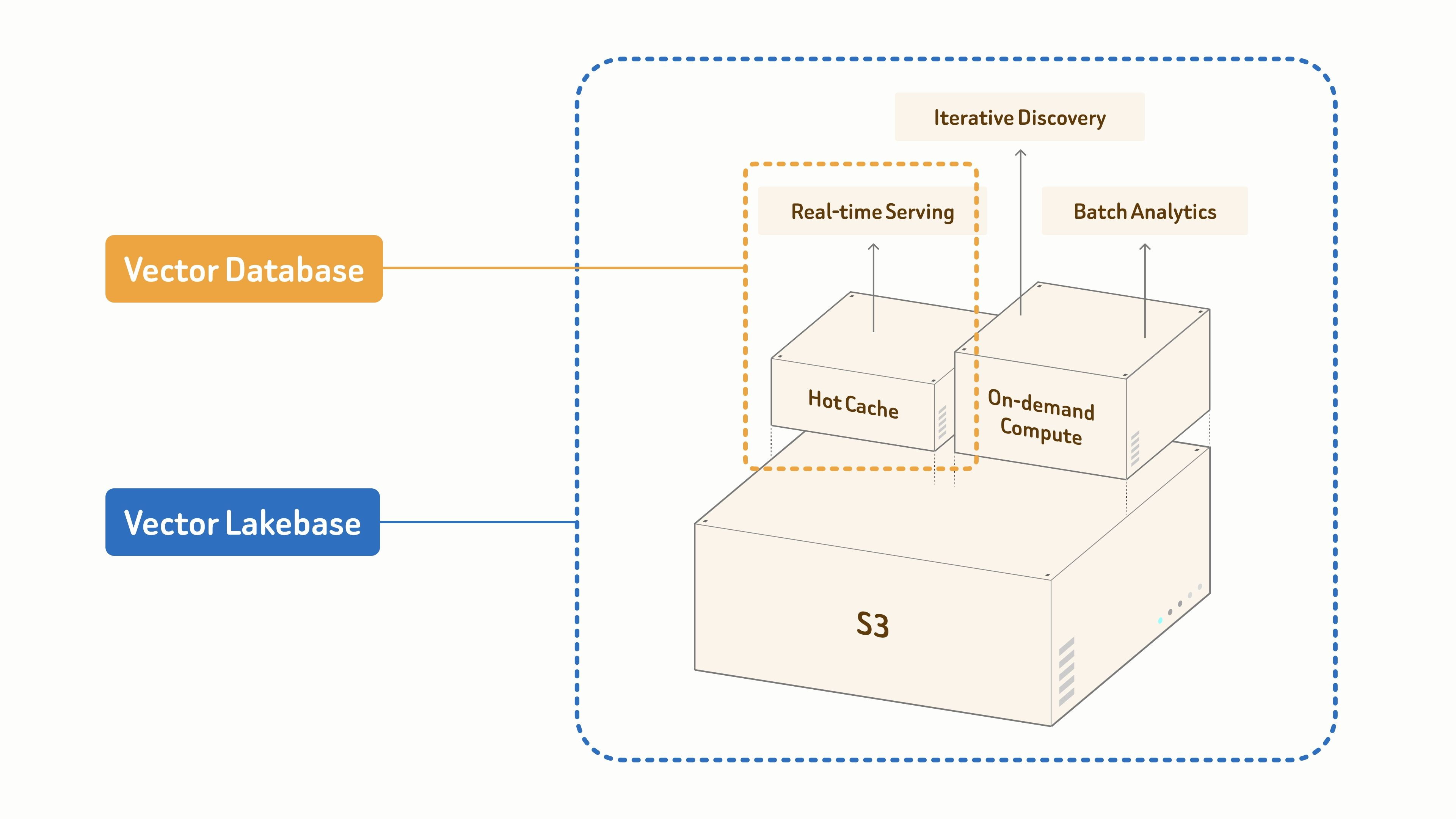
Zilliz Cloud — это полностью управляемая платформа Vector Lakebase, созданная разработчиками Milvus. В ее основе лежит векторная база данных промышленного уровня для высокопроизводительного поиска с низкой задержкой в масштабах до 100 миллиардов векторов. На базе этого ядра Zilliz Cloud расширяет возможности векторного поиска за счет открытости, масштабируемости и экономичности мультимодальных озер данных (data lakes), предоставляя командам единую платформу для поиска, анализа и управления неструктурированными данными для коммерческого ИИ.
Это отлично подходит для библиотеки ассетов Tripo, поскольку данные по своей природе мультимодальны. Каталог 3D-моделей с возможностью поиска должен одновременно работать с рендерами, референсными изображениями, текстовыми описаниями, метаданными генерации, полями принадлежности командам и тегами конкретных проектов. Zilliz Cloud объединяет эти сигналы с помощью векторного поиска и извлечения метаданных, позволяя пользователям находить ассеты по смыслу, визуальному сходству, структурированным фильтрам или комбинации всех трех факторов.
Zilliz подробно описывает эту эволюцию продукта в статьях From Vector Database to Vector Lakebase и Why We Built Vector Lakebase. Главная идея заключается в том, что современным ИИ-системам требуется нечто большее, чем просто поиск по методу ближайших соседей (nearest-neighbor search). Им также нужен фундамент данных для работы в реальном времени, итеративного поиска, пакетной аналитики и управления быстрорастущими неструктурированными наборами данных. Эти потребности напрямую применимы к ИИ-библиотекам 3D-моделей, где командам нужно получать лучшие результаты прямо сейчас и продолжать улучшать каталог со временем.
Обзор рабочего процесса
В этой демонстрации используются три типа локальных данных:
- CSV-файл хранит метаданные для каждого 3D-ассета, такие как категория, стиль, тип объекта, цвет, сценарий использования, имя файла и информация о проекте.
- Папка milvus_render_images/ хранит отрендеренные превью-изображения ассетов, сгенерированных в Tripo. Эти рендеры являются основными целями для поиска.
- Папка milvus_input_images/ содержит референсные изображения, использованные при генерации image-to-3D. Они в основном используются как метаданные и в качестве необязательных референсов для поисковых запросов.
Проще говоря: эта схема позволяет пользователям описать то, что им нужно, загрузить визуальный референс или объединить оба варианта ввода, чтобы найти подходящие ассеты в библиотеке.
Предварительные требования
Перед началом работы убедитесь, что у вас подготовлено следующее:
- Аккаунт Zilliz Cloud. Zilliz Cloud — это полностью управляемая платформа Vector Lakebase, созданная разработчиками Milvus. Она объединяет векторную базу данных промышленного уровня с нативной озерной архитектурой для мультимодальных данных, позволяя сохранять эмбеддинги и структурированные метаданные без необходимости самостоятельно администрировать векторную инфраструктуру. Бесплатного тарифа (free tier) вполне достаточно для работы. Зарегистрируйтесь в Zilliz Cloud, создайте бесплатный кластер и скопируйте его URI и токен.
- API-ключ OpenRouter для мультимодальной модели эмбеддингов Gemini, используемой ниже.
- Python 3.10+ с установленным Milvus Python SDK (
pip install -U pymilvus). См. руководство по установке PyMilvus, если вы сталкиваетесь с этим впервые. - Набор 3D-ассетов, сгенерированных в Tripo — превью рендеров и, при наличии, референсные изображения, использованные для генерации image-to-3D.
Шаг 1: Подготовка данных 3D-ассетов, сгенерированных в Tripo
Первым шагом является подготовка данных, сгенерированных с помощью Tripo.
Каждый ассет должен содержать как минимум:
- Превью-изображение рендера
- Строку метаданных в CSV-файле
- Необязательную информацию об исходном/референсном изображении
- Поля категории, стиля, сценария использования, объекта и цвета (при наличии)
Например, один ассет может содержать следующие метаданные:
| Поле | Пример значения |
|---|---|
| Категория | Персонаж |
| Стиль | Фэнтези |
| Тип объекта | Женщина-воин |
| Цвет | Синий, серебряный |
| Сценарий использования | Игровой ассет |
| Имя файла | warrior_female_01.webp |
Эти метаданные важны, поскольку одного векторного поиска не всегда достаточно. В реальной библиотеке ассетов пользователи часто хотят сочетать семантический поиск с фильтрами.
Например:
- Найти «женского персонажа» со сценарием использования «игровой ассет».
- Найти «фэнтезийный меч с синим драгоценным камнем» в категории «оружие».
- Найти ассеты в определенном визуальном стиле, например: реалистичный, мультяшный, научно-фантастический или low poly.
Чем лучше структура ваших метаданных, тем полезнее будет библиотека ассетов.
Ограничение формата изображений для создания эмбеддингов
Рендеры и исходные референсные изображения хранятся в формате .webp для экономии дискового пространства.
Однако модель эмбеддингов Gemini (gemini-embedding-2-preview) надежно поддерживает только входные данные в форматах PNG и JPEG. Использование изображений WebP может приводить к ошибкам при генерации эмбеддингов в зависимости от бэкенда API.
Поэтому перед генерацией эмбеддингов требуется этап предварительной обработки для конвертации изображений в PNG или JPEG.
Шаг 2: Создание коллекции в Zilliz Cloud
В Zilliz Cloud каждая запись в коллекции представляет собой один сгенерированный в Tripo 3D-ассет.
Именно здесь модель Vector Lakebase раскрывает свои преимущества. Традиционная векторная база данных отлично справляется с поиском сходства в реальном времени. В то же время Vector Lakebase сохраняет этот механизм поиска, добавляя общую платформу данных на основе озера данных для работы с мультимодальной информацией, пакетной аналитики, исследования и управления. В этой демонстрации мы используем упрощенный вариант, но эта структура легко масштабируется под гораздо более крупную библиотеку ассетов Tripo.
Коллекция хранит как структурированные метаданные, так и мультимодальный вектор. Ключевым векторным полем является multimodal_vector. В этой демонстрации размерность вектора составляет 3072, а в качестве метрики сходства используется COSINE.
Поскольку текстовые, графические и комбинированные (текст + изображение) запросы проецируются в одно и то же векторное пространство, система может искать по всем ассетам, используя одно унифицированное векторное поле.
Ниже приведена упрощенная настройка схемы:
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
Затем создайте векторный индекс:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
После определения схемы и индекса выполните:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
После завершения выполнения команды вы сможете увидеть созданную коллекцию в консоли Zilliz Cloud.
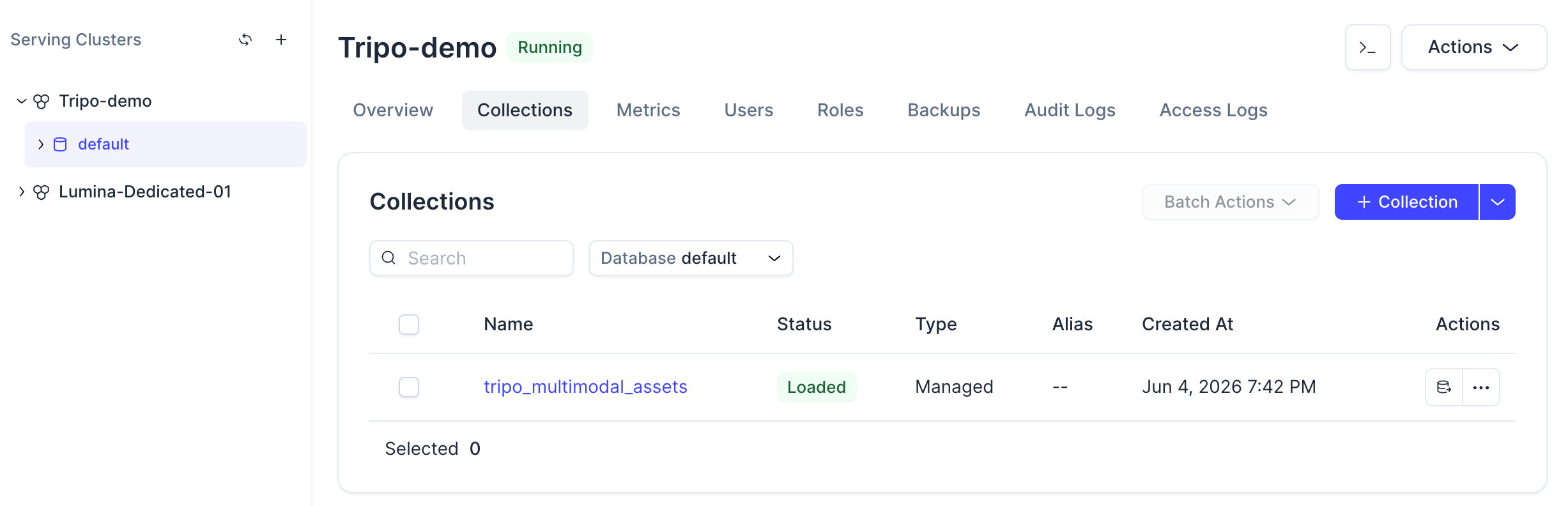
Нажав на коллекцию, вы также можете просмотреть ее статус, схему, загруженные сущности и конфигурацию векторного поля.
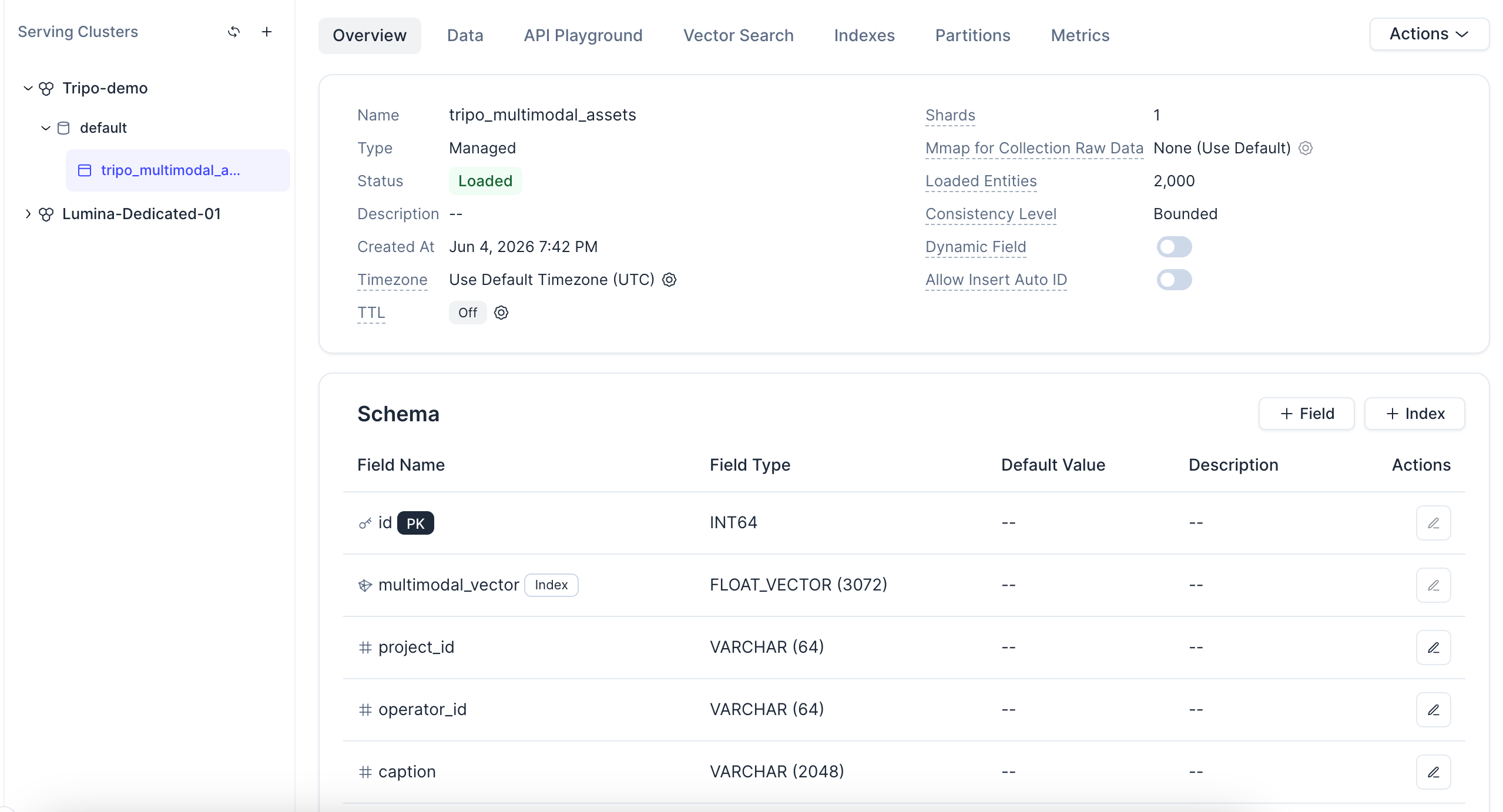
Примечание по поводу индекса: в этой демонстрации используется AUTOINDEX, что позволяет Zilliz Cloud автоматически выбирать и оптимизировать векторный индекс на основе ваших данных — без необходимости вручную подбирать типы индексов или параметры. Тип метрики COSINE соответствует нормализованным по L2 эмбеддингам, создаваемым на следующем шаге. И поскольку каждая запись представляет собой одну сущность в управляемой коллекции, такая конфигурация масштабируется от сотен до миллионов ассетов без изменения архитектуры.
Шаг 3: Генерация эмбеддингов для рендеров
Далее сгенерируйте эмбеддинги для превью-изображений рендеров Tripo.
В этом процессе изображения рендеров преобразуются в строки base64 data URL и отправляются в модель эмбеддингов. Полученные векторы нормализуются для возможности их использования с поиском сходства по метрике COSINE.
Вот основная логика кода:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
Чтобы создать кэш эмбеддингов для всего набора данных, выполните:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
Этап кэширования полезен, поскольку генерация эмбеддингов может занимать много времени и зависит от доступности API. Вместо создания эмбеддингов при каждом импорте данных вы можете создать кэш один раз и использовать его повторно в процессе импорта.

После генерации кэша эмбеддингов каждая строка в CSV преобразуется в одну сущность (entity) Zilliz Cloud.
Каждая сущность включает в себя:
- Asset ID
- Project ID
- Operator ID
- Caption
- Метаданные, сгенерированные LLM
- Режим генерации
- Информация о файле рендера изображения
- Информация о файле исходного изображения
- Мультимодальный вектор
Вот упрощенная версия функции конвертации сущностей:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
Затем импортируйте весь набор данных:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
После завершения импорта откройте консоль Zilliz Cloud и перейдите на вкладку Data. Вы должны увидеть импортированные записи ассетов, включая поля метаданных и информацию о векторах.
На этом этапе сгенерированные Tripo 3D-ассеты перестают быть просто локальными файлами. Теперь они представляют собой доступные для поиска сущности в векторной базе данных.
Шаг 5: Поиск по библиотеке 3D-ассетов
Система поиска поддерживает три режима запросов:
- Текстовый поиск — поиск по семантическому описанию
- Поиск по изображению — поиск по визуальному сходству
- Поиск по тексту и изображению — сочетание обоих вариантов для более точного поиска
Все три типа запросов преобразуются в векторы с использованием той же мультимодальной модели эмбеддингов. Затем вектор запроса ищется по полю multimodal_vector в Zilliz Cloud.
Текстовый поиск
Текстовый поиск полезен, когда пользователь уже знает, что ему нужно.
Пример запроса: "A female character with blue and silver armor" (Женский персонаж в сине-серебряных доспехах)
Система строит эмбеддинг текстового запроса, выполняет поиск по коллекции и возвращает наиболее подходящие изображения рендеров с метаданными.
Это особенно полезно для творческих команд, которые хотят искать по семантическому смыслу, а не по точным именам файлов. Например, дизайнеру не нужно помнить, называется ли файл char_f_warrior_01 или f_warrior_blue. Он может просто ввести в поиск: "female warrior blue armor". В этом и заключается разница между файловым архивом и полноценной системой поиска ассетов.
Поиск по изображению
Поиск по изображению полезен, когда у пользователя есть референс и он хочет найти визуально похожие 3D-ассеты.
Например, игровой художник может загрузить референсное изображение стилизованного щита и найти похожие пропсы, сгенерированные Tripo, в существующей библиотеке. Вместо того чтобы вручную просматривать сотни изображений, система найдет ассеты, соответствующие визуальной структуре, стилю или концепции объекта на загруженном референсе.
Поиск по тексту и изображению
Поиск по сочетанию текста и изображения — это наиболее гибкий вариант. Он позволяет пользователю объединить семантическое описание с визуальным ориентиром.
Например, пользователь может загрузить референс меча и добавить текстовый запрос: "fantasy sword with blue gemstone". Изображение задает визуальный ориентир, а текст конкретизирует намерение поиска. Это делает результаты поиска более точными, чем при использовании только одного из этих входных параметров.
Вот упрощенная логика поиска:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
Возвращаемые результаты содержат как оценки сходства (similarity scores), так и метаданные, что позволяет отображать превью найденных ассетов в пользовательском интерфейсе.
Обратите внимание, что поиск не ограничивается только сходством векторов. Поскольку каждый ассет также содержит структурированные метаданные (категорию, стиль, сферу применения и т. д.), вы можете объединить семантическое сходство с условиями фильтрации по метаданным в одном запросе — например, искать "female", но ограничить результаты условием llm_use_case == "game asset". Это отфильтрованный поиск, и именно он превращает простой набор векторов в структурированный каталог ассетов, по которому можно делать запросы. Если позже вам понадобится сопоставлять данные по нескольким признакам одновременно, Zilliz Cloud также поддерживает мультивекторный гибридный поиск по нескольким эмбеддингам для каждого ассета.
Пример 1: Поиск по тексту и сфере применения
В демо-версии один из примеров запроса использует текст "female" с фильтром сферы применения llm_use_case == "game asset" и параметром limit=12.
Это возвращает топ-12 наиболее подходящих ассетов, которые семантически связаны с "female" и относятся к сфере применения "игровой ассет".
Такой тип поиска крайне полезен в пайплайнах разработки игр, когда командам нужно быстро находить концепты персонажей, дизайны NPC, стилизованные аватары или гуманоидные ассеты в большой внутренней библиотеке.
Пример 2: Поиск по тексту и референсному изображению
Другой пример сочетает текстовый запрос с референсным изображением.
Текстовый запрос: "Fantasy style weapon with detailed ornamentation and glowing effects". Запрос также включает визуальный референс. Затем система генерирует один совместный эмбеддинг для текста и изображения, выполняет поиск по тому же векторному полю и возвращает наиболее релевантные изображения рендеров.
Это полезно, когда намерение пользователя слишком сложно выразить только текстом. Для поиска визуальных ассетов подход "похоже на это, но ближе к тому" — это именно то, как обычно мыслят создатели контента.
Почему этот рабочий процесс важен
Реальная ценность здесь заключается не только в поиске по изображениям — это инфраструктура для повторного использования созданных ИИ 3D-ассетов. Tripo обеспечивает быструю генерацию, а Zilliz Cloud отвечает за хранение векторов, поиск по сходству, извлечение метаданных и слой данных для мультимодального поиска. Вместе они превращают разрозненные 3D-результаты в организованную, доступную для поиска и повторного использования библиотеку, что напрямую повышает эффективность производства для команд, создающих 3D-контент в больших масштабах.
Поскольку Zilliz Cloud создана для продакшн-решений на базе ИИ, эту модель можно внедрить на начальном этапе и масштабировать по мере роста команды. Игровые студии могут находить варианты персонажей, пропсов и окружения; команды электронной коммерции — организовывать модели товаров по категориям, цветам или материалам; отделы маркетинга — повторно использовать существующие визуальные материалы вместо их повторной генерации; а команды креативного продакшна — вести централизованное, удобное для поиска хранилище утвержденных ассетов для всех проектов.
Заключение
Генерация 3D с помощью ИИ сейчас происходит достаточно быстро, и создание моделей больше не является единственным узким местом. Следующая задача — это то, что происходит после генерации модели: как она хранится, находится, управляется и используется повторно, а не просто теряется в недрах папок.
Этот рабочий процесс связывает Tripo и Zilliz Cloud для решения именно этой задачи: Tripo генерирует высококачественные ассеты по текстовым описаниям или референсам, а Zilliz Cloud добавляет слой поиска и извлечения — изображения рендеров, мультимодальные эмбеддинги, структурированные метаданные и масштабируемый поиск по векторам. Иными словами, Tripo становится движком создания 3D, а Zilliz Cloud — инфраструктурой данных ИИ, которая делает эти творения доступными для поиска, повторного использования и готовыми к интеграции в следующий проект.
Попробуйте сами
Генерация 3D с помощью ИИ — это лишь первый шаг. Настоящая выгода заключается в превращении сгенерированных ассетов в структурированную, удобную для поиска систему, которая масштабируется на уровне команд и проектов. С помощью Tripo вы создаете высококачественные 3D-ассеты на основе текстовых промптов или референсных изображений. С Zilliz Cloud вы систематизируете и находите их с помощью мультимодального векторного поиска по тексту и изображениям на базе управляемой векторной базы данных (Vector Lakebase), созданной для рабочих процессов ИИ в продакшне.
- Зарегистрируйтесь в Zilliz Cloud и пройдите это руководство от начала до конца на бесплатном тарифе.
- Генерируйте свои 3D-ассеты с помощью Tripo
