Crie uma Biblioteca de Assets 3D de IA Pesquisável com Tripo e Zilliz
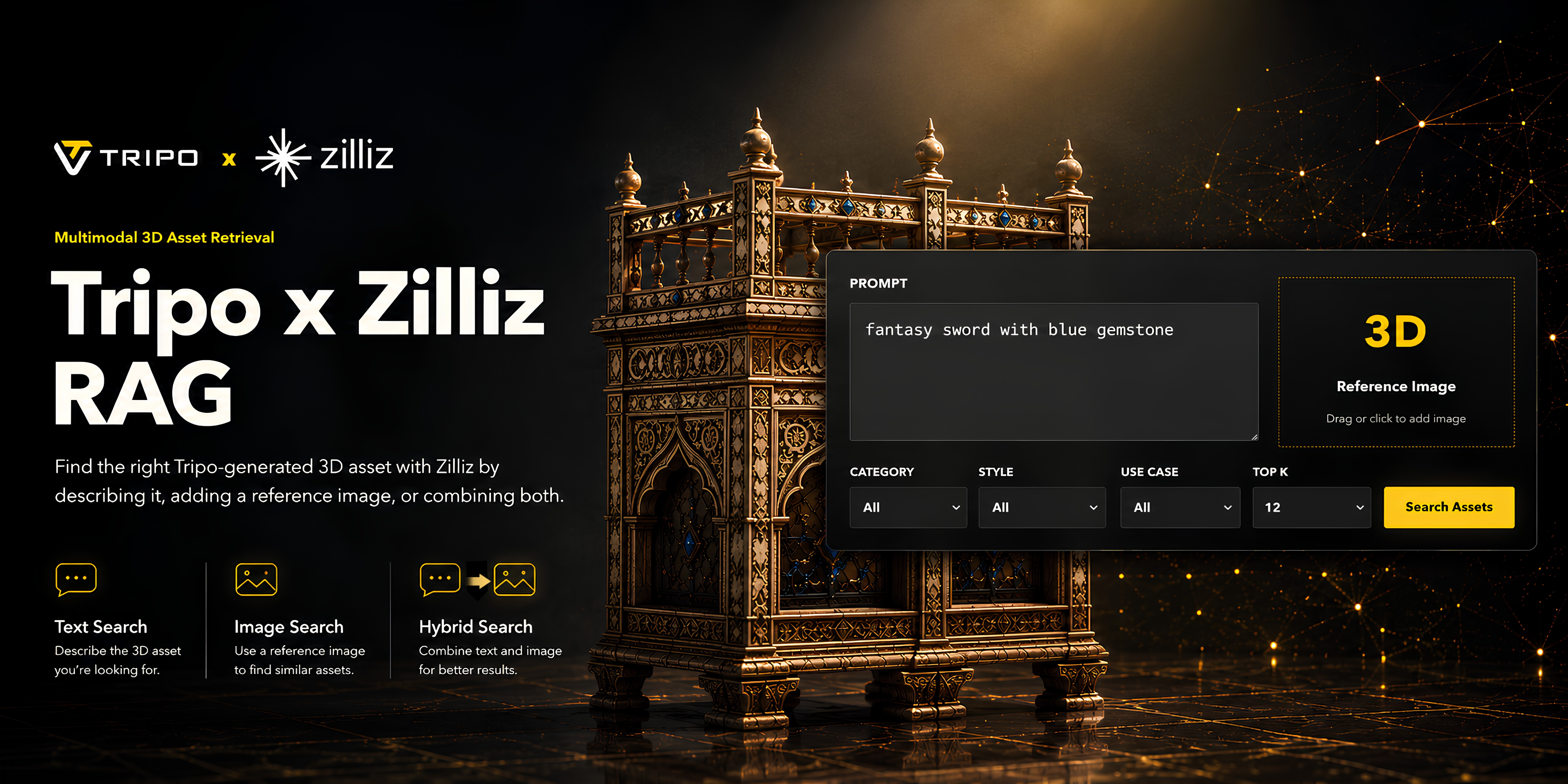
A geração 3D de IA está tornando drasticamente mais fácil para as equipes criarem assets 3D em escala. Com o Tripo, os criadores podem gerar modelos 3D de alta qualidade a partir de prompts de texto ou imagens de referência, tornando-o útil para desenvolvimento de jogos, visualização de e-commerce, produção de marketing, concept design e fluxos de trabalho criativos internos.
Mas assim que o número de assets gerados cresce, um novo problema aparece.
Como encontrar o asset 3D correto rapidamente?
Quando uma equipe tem apenas alguns modelos, nomes de pastas e navegação manual podem ser suficientes. Mas quando há centenas ou milhares de assets gerados, a abordagem tradicional de gerenciamento de arquivos começa a falhar. Os designers podem gerar assets semelhantes repetidamente. As equipes de jogos podem perder o controle de variações úteis de personagens ou props. As equipes de marketing podem gastar mais tempo procurando assets do que usando-os.
É aí que uma biblioteca de assets 3D de IA pesquisável se torna valiosa.
Neste fluxo de trabalho, o Tripo gera os assets 3D, enquanto o Zilliz Cloud atua como a camada de recuperação para vetores multimodais e metadados. Ele armazena os embeddings que representam cada imagem de renderização (render image) e os conecta a campos úteis, como categoria, estilo, cor, tipo de objeto, caso de uso e arquivo de origem. O resultado é um sistema leve de recuperação multimodal no qual os usuários podem pesquisar com texto, uma imagem de referência ou ambos, e obter de volta imagens de renderização correspondentes geradas pelo Tripo com metadados estruturados.
A Zilliz é uma empresa de infraestrutura de dados de IA e criadora do Milvus, o banco de dados vetorial de código aberto por trás deste fluxo de trabalho. O Milvus foi desenvolvido para casos de uso de IA em produção, como RAG, agentes de IA, busca multimodal, sistemas de recomendação, bases de conhecimento corporativas, busca semântica e deduplicação de conteúdo. É também um projeto graduado da Linux Foundation AI & Data com mais de 44.000 estrelas no GitHub e mais de 100 milhões de downloads no Docker, oferecendo às equipes uma base familiar para armazenar e recuperar embeddings vetoriais de dados não estruturados.
Isso é importante para os usuários do Tripo porque cada asset 3D é mais do que um único arquivo. Cada modelo pode ser conectado a uma prévia de renderização (render preview), uma imagem de referência de entrada, uma legenda (caption), tags, categorias, cores, casos de uso, IDs de projeto e URLs. O Zilliz Cloud torna esses sinais pesquisáveis em conjunto, de modo que uma biblioteca crescente de modelos gerados por IA pode se tornar um sistema de assets de produção reutilizável, em vez de uma pasta de saídas únicas.
Por que Criar uma Biblioteca de Assets 3D Pesquisável
As ferramentas de IA 3D são excelentes na velocidade de produção. Um único criador agora pode gerar múltiplos conceitos de personagens, mockups de produtos, props, elementos de cenário ou assets estilizados em um espaço de tempo muito curto.
No entanto, a velocidade cria volume. O volume cria problemas de gerenciamento.
Uma biblioteca de assets 3D pesquisável ajuda a resolver vários problemas comuns:
- As equipes podem encontrar rapidamente assets existentes em vez de gerar duplicatas.
- Os designers podem pesquisar por conceito, estilo, cor, tipo de objeto ou caso de uso.
- Os desenvolvedores podem reutilizar assets 3D em diferentes projetos de forma mais eficiente.
- As equipes criativas podem construir uma biblioteca interna de materiais visuais aprovados e reutilizáveis.
- As equipes de e-commerce ou marketing podem organizar assets 3D semelhantes a produtos por categoria e estilo.
Em vez de tratar os arquivos 3D gerados por IA como saídas únicas, este fluxo de trabalho os transforma em um sistema de assets reutilizável.
Por que o Zilliz Cloud é Ideal para Busca Multimodal de Assets 3D
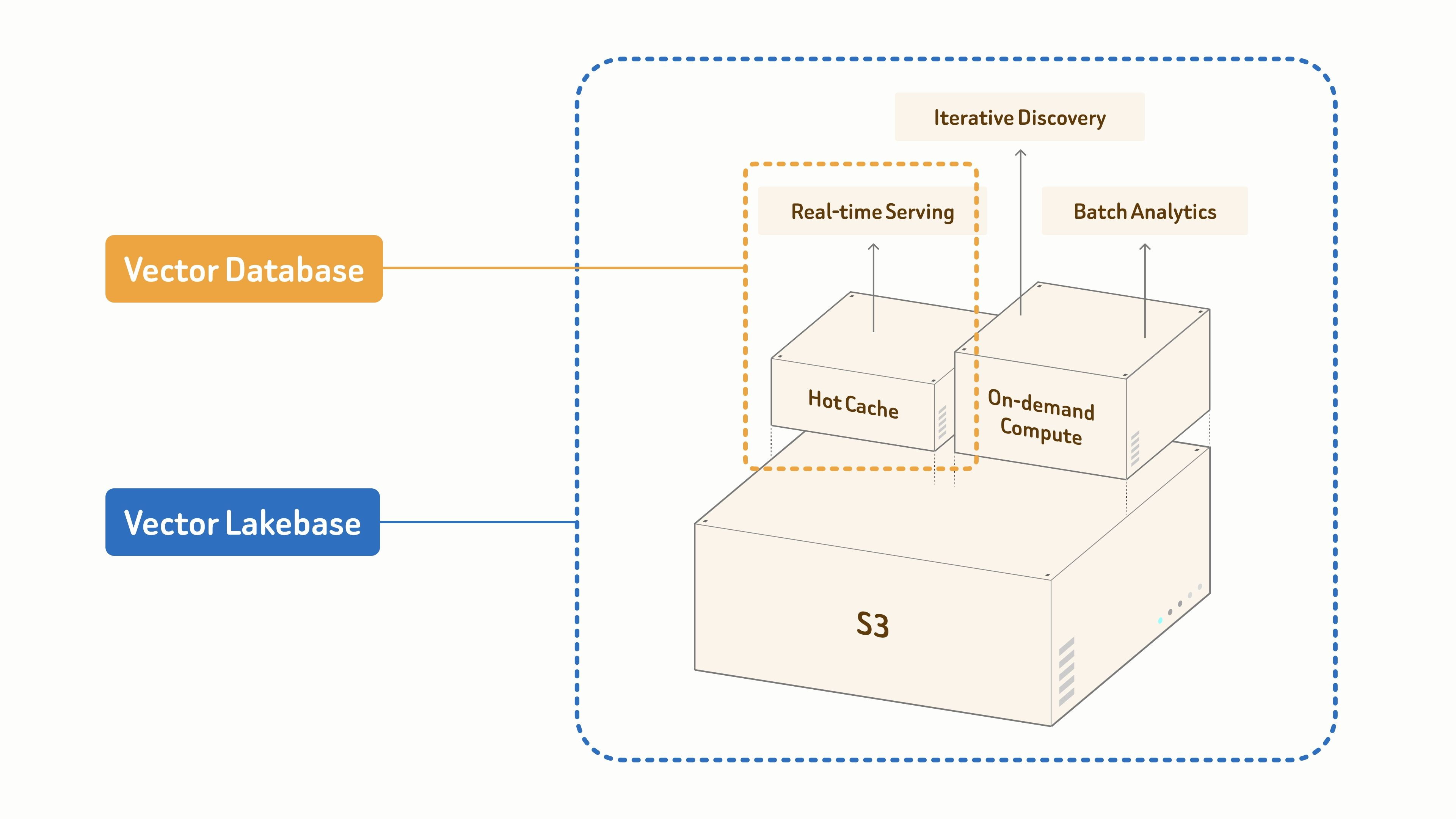
O Zilliz Cloud é uma plataforma de Vector Lakebase totalmente gerenciada, criada pelos criadores do Milvus. Em seu núcleo está um banco de dados vetorial de nível de produção para busca vetorial de alto rendimento e baixa latência em escala de 100 bilhões de vetores. Em torno desse núcleo, o Zilliz Cloud estende a busca vetorial com a abertura, escalabilidade e economia dos data lakes multimodais, oferecendo às equipes uma única plataforma para pesquisar, analisar e governar dados não estruturados para IA em produção.
Isso se adapta perfeitamente a uma biblioteca de assets do Tripo porque os dados são multimodais por natureza. Um catálogo 3D pesquisável pode precisar funcionar com imagens de renderização, imagens de referência, legendas de texto, metadados gerados, campos de propriedade da equipe e tags específicas do projeto ao mesmo tempo. O Zilliz Cloud conecta esses sinais por meio de busca vetorial e recuperação de metadados, para que os usuários possam encontrar assets por significado, semelhança visual, filtros estruturados ou uma combinação de todos os três.
A Zilliz explica essa evolução do produto em From Vector Database to Vector Lakebase e Why We Built Vector Lakebase. A ideia principal é que os sistemas modernos de IA precisam de mais do que a busca do vizinho mais próximo (nearest-neighbor search). Eles também precisam de uma base de dados para serviço em tempo real, descoberta iterativa, análise em lote (batch analytics) e governança sobre conjuntos de dados não estruturados em rápido crescimento. Essas necessidades se alinham diretamente com as bibliotecas de IA 3D, onde as equipes desejam recuperar o melhor resultado de hoje e continuar aprimorando o catálogo ao longo do tempo.
Visão Geral do Fluxo de Trabalho
Esta demonstração usa três tipos de dados locais:
- O arquivo CSV armazena os metadados para cada asset 3D, como categoria, estilo, tipo de objeto, cor, caso de uso, nome do arquivo e informações de projeto relacionadas.
- A pasta milvus_render_images/ armazena as imagens de visualização renderizadas dos assets gerados pelo Tripo. Essas imagens de renderização são os principais alvos de recuperação.
- A pasta milvus_input_images/ armazena as imagens de referência usadas durante a geração de image-to-3D. Elas são usadas principalmente como metadados e como referências de consulta opcionais.
Em termos simples: esta configuração permite que os usuários descrevam o que precisam, enviem uma referência visual ou combinem ambas as entradas para encontrar assets relevantes na biblioteca.
Pré-requisitos
Antes de começar, certifique-se de ter o seguinte:
- Uma conta no Zilliz Cloud. O Zilliz Cloud é uma plataforma de Vector Lakebase totalmente gerenciada, criada pelos criadores do Milvus. Ele combina um banco de dados vetorial de nível de produção com uma base nativa de data lake para dados multimodais, permitindo que você armazene embeddings e metadados estruturados sem precisar operar a infraestrutura vetorial por conta própria. O plano gratuito é suficiente para acompanhar o tutorial. Inscreva-se no Zilliz Cloud, crie um cluster gratuito e obtenha sua URI e token.
- Uma chave de API do OpenRouter para o modelo de embedding multimodal Gemini usado abaixo.
- Python 3.10+ com o SDK Python do Milvus instalado (
pip install -U pymilvus). Consulte o guia de instalação do PyMilvus se for iniciante. - Um conjunto de assets 3D gerados pelo Tripo — imagens de visualização de renderização e, opcionalmente, as imagens de referência usadas para a geração image-to-3D.
Passo 1: Preparar os Dados de Assets 3D Gerados pelo Tripo
O primeiro passo é preparar os dados gerados através do Tripo.
Cada asset deve ter pelo menos:
- Uma imagem de visualização de renderização (render preview)
- Uma linha de metadados no CSV
- Informações opcionais de imagem de entrada/referência
- Campos de categoria, estilo, caso de uso, objeto e cor, quando disponíveis
Por exemplo, um asset pode incluir metadados como este:
| Campo | Valor de Exemplo |
|---|---|
| Categoria | Personagem |
| Estilo | Fantasia |
| Tipo de Objeto | Guerreira feminina |
| Cor | Azul, Prata |
| Caso de Uso | Asset de jogo |
| Nome do Arquivo | warrior_female_01.webp |
Esses metadados são importantes porque apenas a busca vetorial nem sempre é suficiente. Em uma biblioteca de assets real, os usuários frequentemente desejam combinar a busca semântica com filtros.
Por exemplo:
- Encontrar um "personagem feminino" no caso de uso "asset de jogo".
- Encontrar "espada de fantasia com gema azul" sob a categoria "arma".
- Encontrar assets em um estilo visual específico, como realista, cartoon, ficção científica (sci-fi) ou low poly.
Quanto melhor for a estrutura dos seus metadados, mais útil se tornará a sua biblioteca de assets.
Restrição de Formato de Imagem para Embedding
As imagens de renderização e as imagens de referência de entrada são armazenadas no formato .webp para eficiência de armazenamento.
No entanto, o modelo de embedding Gemini (gemini-embedding-2-preview) suporta de forma confiável apenas entradas em PNG e JPEG. Imagens WebP podem causar falhas de geração de embedding dependendo do backend da API.
Portanto, é necessária uma etapa de pré-processamento para converter as imagens para PNG ou JPEG antes de gerar os embeddings.
Passo 2: Criar uma Coleção no Zilliz Cloud
No Zilliz Cloud, cada registro na coleção representa um asset 3D gerado pelo Tripo.
É aqui que o modelo de Vector Lakebase se torna útil. Um banco de dados vetorial tradicional é excelente para busca por similaridade em tempo real. Um Vector Lakebase mantém esse caminho de recuperação ao mesmo tempo que adiciona uma base de dados compartilhada, nativa de data lake, para dados multimodais, análises em lote, descoberta iterativa e governança. Nesta demonstração, nós o usamos de forma leve, mas a mesma estrutura pode crescer junto com uma biblioteca de assets do Tripo muito maior.
A coleção armazena metadados estruturados e um vetor multimodal. O campo vetorial principal é multimodal_vector. Nesta demonstração, a dimensão do vetor é 3072, e a métrica COSINE é usada como a métrica de similaridade.
Como as consultas de texto, imagem e texto-mais-imagem são incorporadas no mesmo espaço vetorial, o sistema pode pesquisar todos os assets usando um campo vetorial unificado.
Aqui está a configuração simplificada do esquema (schema):
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
Em seguida, crie o índice vetorial:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
Depois de definir o esquema e o índice, execute:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
Assim que o comando for concluído, você poderá ver a coleção no console do Zilliz Cloud.
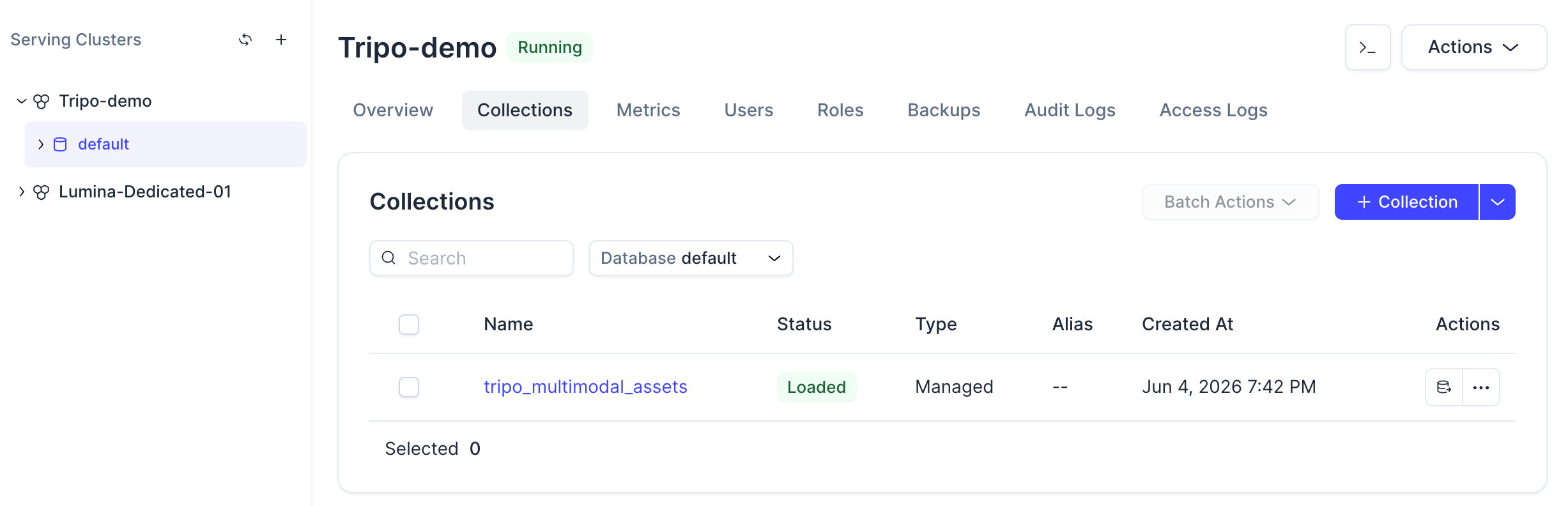
Clique na coleção e você também poderá visualizar seu status, esquema, entidades carregadas e configuração do campo vetorial.
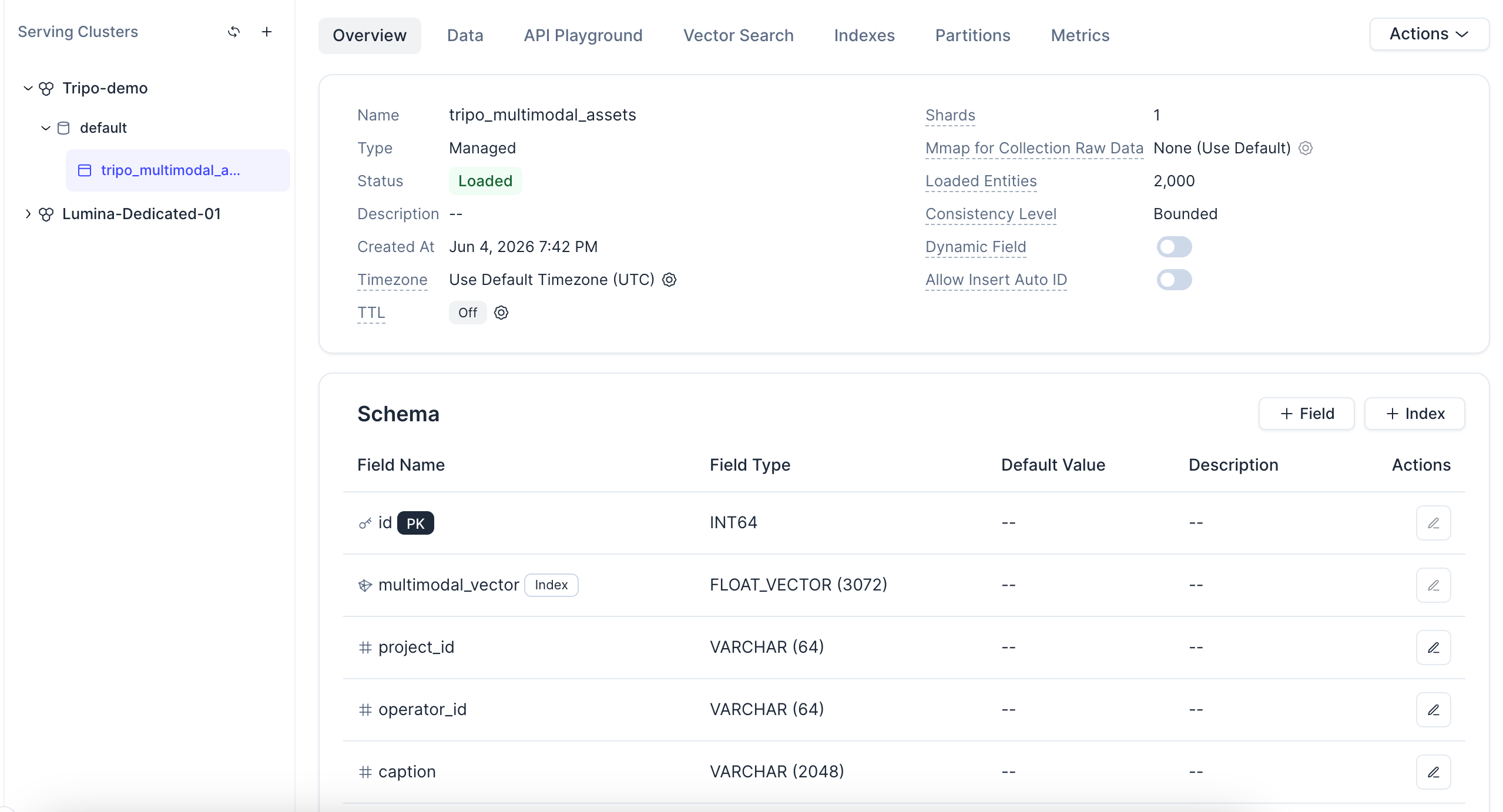
Uma nota sobre o índice: esta demonstração usa o AUTOINDEX, que permite ao Zilliz Cloud escolher e ajustar o índice vetorial para você com base nos seus dados — sem a necessidade de selecionar manualmente tipos de índice ou parâmetros. O tipo de métrica COSINE corresponde aos embeddings normalizados por L2 gerados na próxima etapa. E como cada registro é uma entidade em uma coleção gerenciada, essa mesma configuração escala de centenas de assets para milhões sem a necessidade de reestruturação de arquitetura.
Passo 3: Gerar Embeddings para Imagens de Renderização
Em seguida, gere os embeddings para as imagens de visualização de renderização do Tripo.
Neste fluxo de trabalho, as imagens de renderização são convertidas em URLs de dados base64 e enviadas para um modelo de embedding. Os vetores retornados são normalizados para que possam ser usados com a busca por similaridade COSINE.
Aqui está a lógica principal:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
Para construir o cache de embeddings para todo o conjunto de dados, execute:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
A etapa de cache é útil porque a geração de embeddings pode ser demorada e dependente de API. Em vez de gerar embeddings toda vez que você importar dados, você pode construir o cache uma vez e reutilizá-lo durante o processo de importação.

Após gerar o cache de embedding, cada linha no CSV é convertida em uma entidade do Zilliz Cloud.
Cada entidade inclui:
- Asset ID
- Project ID
- Operator ID
- Caption
- Metadados gerados por LLM
- Modo de geração
- Informações do arquivo da imagem de renderização
- Informações do arquivo da imagem de entrada
- Vetor multimodal
Aqui está uma versão simplificada da função de conversão de entidade:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
Em seguida, importe o dataset completo:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
Após a conclusão da importação, abra o console do Zilliz Cloud e verifique a aba Data. Você deverá ver os registros dos assets importados, incluindo os campos de metadados e as informações dos vetores.
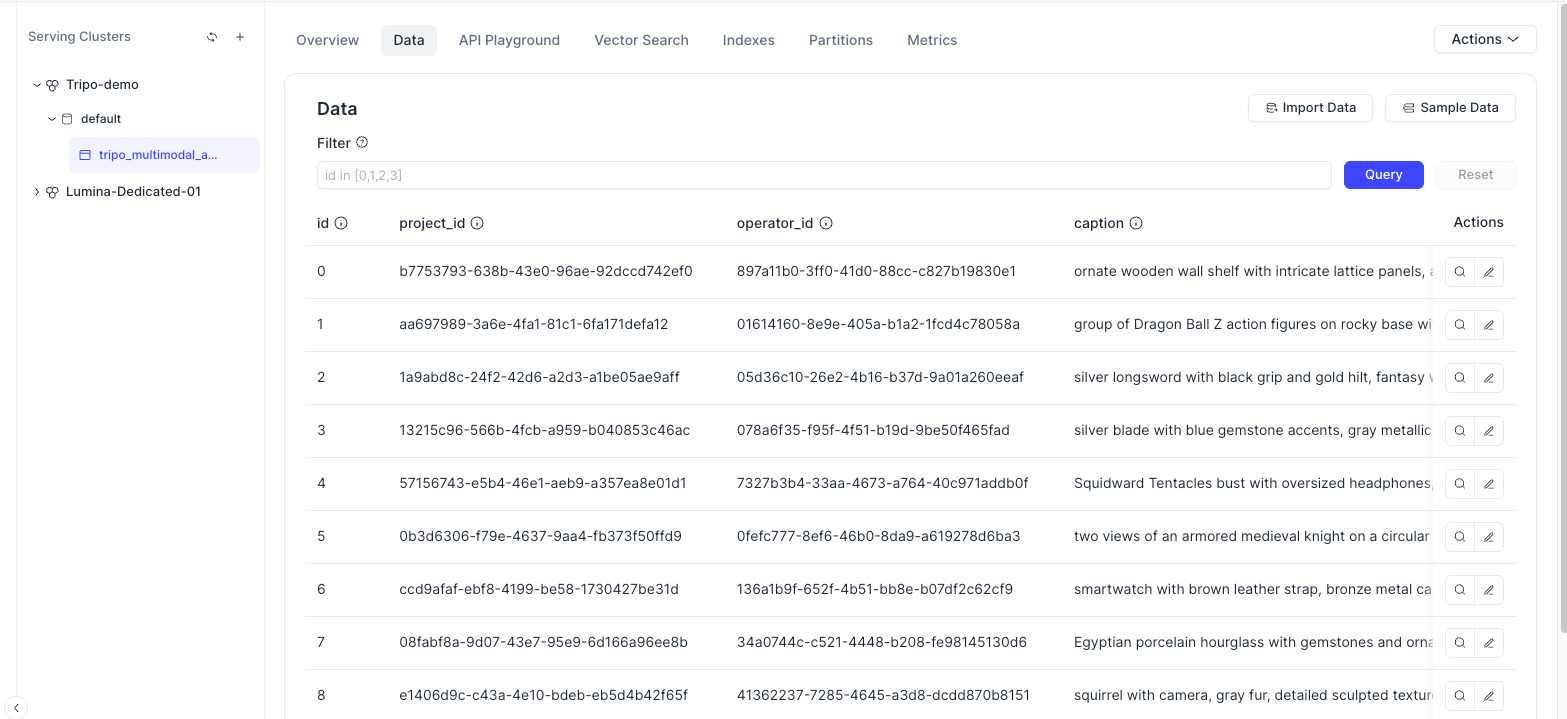
Neste ponto, os assets 3D gerados pelo Tripo não são mais apenas arquivos locais. Eles agora são entidades pesquisáveis em um banco de dados vetorial.
Passo 5: Buscar na Biblioteca de Assets 3D
O sistema de busca suporta três modos de consulta:
- Busca por Texto — busca por descrição semântica
- Busca por Imagem — busca por similaridade visual
- Busca por Texto + Imagem — combina ambos para uma recuperação mais precisa
Todos os três tipos de consulta são convertidos em vetores usando o mesmo modelo de embedding multimodal. Em seguida, o vetor da consulta é buscado no campo multimodal_vector no Zilliz Cloud.
Busca por Texto
A busca por texto é útil quando o usuário já sabe o que deseja.
Exemplo de consulta: "Um personagem feminino com armadura azul e prateada"
O sistema gera o embedding da consulta de texto, busca na coleção e retorna as imagens de renderização mais próximas com seus metadados.
Isso é especialmente útil para equipes criativas que desejam buscar por intenção semântica em vez de nomes de arquivos exatos. Por exemplo, um designer não precisa lembrar se um arquivo se chama char_f_warrior_01 ou f_warrior_blue. Eles podem simplesmente buscar por: "female warrior blue armor". Essa é a diferença entre um arquivo de armazenamento e um sistema real de recuperação de assets.
Busca por Imagem
A busca por imagem é útil quando o usuário tem uma imagem de referência e deseja encontrar assets 3D visualmente semelhantes.
Por exemplo, um artista de jogos pode fazer o upload de uma imagem de referência de um escudo estilizado e buscar por props semelhantes gerados pelo Tripo na biblioteca existente. Em vez de navegar manualmente por centenas de imagens, o sistema pode recuperar assets que correspondam à estrutura visual, estilo ou conceito do objeto da referência enviada.
Busca por Texto + Imagem
A busca de texto mais imagem é a opção mais flexível. Ela permite ao usuário combinar a intenção semântica com a orientação visual.
Por exemplo, o usuário pode fazer o upload de uma imagem de referência de uma espada e adicionar uma consulta de texto: "fantasy sword with blue gemstone" (espada de fantasia com gema azul). A imagem fornece a referência visual, enquanto o texto refina a intenção de busca. Isso torna a recuperação muito mais específica do que usar apenas uma das entradas isoladamente.
Aqui está a lógica de busca simplificada:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
Os resultados retornados incluem tanto as pontuações de similaridade quanto os metadados, tornando possível exibir as prévias dos assets correspondentes em uma interface front-end.
Observe que a busca não se limita à pura similaridade vetorial. Como cada asset também carrega metadados estruturados (categoria, estilo, caso de uso e mais), você pode combinar similaridade semântica com condições de metadados em uma única requisição — por exemplo, buscar por "female" mas restringir os resultados a llm_use_case == "game asset". Isso é a busca filtrada (filtered search), e é o que transforma um amontoado de vetores em um catálogo de assets consultável. Se mais tarde você quiser fazer a correspondência de múltiplos sinais de uma só vez, o Zilliz Cloud também suporta busca híbrida multi-vetorial (multi-vector hybrid search) em múltiplos embeddings por asset.
Exemplo 1: Busca por Texto e Caso de Uso
No demo, um exemplo de consulta utiliza o texto "female" com o filtro de caso de uso llm_use_case == "game asset" e define limit=12.
Isso recupera os 12 principais assets correspondentes que estão semânticamente relacionados a "female" e pertencem ao caso de uso de asset de jogo (game asset).
Esse tipo de busca é útil para pipelines de desenvolvimento de jogos, onde as equipes precisam localizar rapidamente conceitos de personagens, designs de NPCs, avatares estilizados ou assets humanoides a partir de uma grande biblioteca interna.
Exemplo 2: Busca por Texto e Imagem de Referência
Outro exemplo combina uma consulta de texto com uma imagem de referência.
A consulta de texto é: "Fantasy style weapon with detailed ornamentation and glowing effects" (Arma em estilo de fantasia com ornamentação detalhada e efeitos brilhantes). A consulta também inclui uma imagem de referência visual. O sistema então gera um único embedding conjunto para o texto e a imagem juntos, pesquisa no mesmo campo vetorial e retorna as imagens de renderização mais relevantes.
Isso é útil quando a intenção do usuário é específica demais apenas para o texto. Para busca de assets visuais, "semelhante a isso, mas mais parecido com aquilo" é frequentemente a forma exata como os criadores pensam.
Por que este fluxo de trabalho é importante
O valor real aqui não é apenas a busca por imagem — é a infraestrutura de assets 3D de IA reutilizável. O Tripo cuida da geração rápida; o Zilliz Cloud cuida do armazenamento vetorial, busca por similaridade, recuperação de metadados e da camada de dados por trás da busca multimodal. Juntos, eles transformam resultados 3D isolados em uma biblioteca organizada, pesquisável e reutilizável, o que melhora diretamente a eficiência de produção para equipes que criam conteúdo 3D em escala.
Como o Zilliz Cloud foi desenvolvido para IA em produção, o mesmo padrão pode começar pequeno e escalar com a equipe. Estúdios de jogos podem localizar variações de personagens, props e ambientes; equipes de e-commerce podem organizar modelos de produtos por categoria, cor ou material; equipes de marketing podem reutilizar recursos visuais existentes em vez de gerá-los novamente; e equipes de operações criativas (creative-ops) podem manter um repositório central e pesquisável de assets aprovados entre diferentes projetos.
Conclusão
A geração 3D por IA agora é rápida o suficiente para que a criação não seja mais o único gargalo. O próximo desafio é o que acontece após um modelo ser gerado — como ele é armazenado, reencontrado, governado e reutilizado em vez de desaparecer em uma pasta.
Este fluxo de trabalho conecta o Tripo e o Zilliz Cloud para resolver exatamente isso: o Tripo gera assets de alta qualidade a partir de texto ou imagens de referência, e o Zilliz Cloud adiciona a camada de recuperação — imagens de renderização, embeddings multimodais, metadados estruturados e busca vetorial escalável. Em outras palavras, o Tripo torna-se o motor de criação 3D, enquanto o Zilliz Cloud torna-se a infraestrutura de dados de IA que mantém essas criações pesquisáveis, reutilizáveis e prontas para o próximo projeto.
Experimente Você Mesmo
A geração 3D por IA é apenas o primeiro passo — o retorno real vem ao transformar os assets gerados em um sistema estruturado e pesquisável que escala entre equipes e projetos. Com o Tripo, você gera assets 3D de alta qualidade a partir de prompts de texto ou imagens de referência. Com o Zilliz Cloud, você os organiza e recupera por meio de busca vetorial multimodal em texto e imagens, apoiado por um Vector Lakebase gerenciado projetado para fluxos de trabalho de IA em produção.
- Inscreva-se no Zilliz Cloud e siga este tutorial de ponta a ponta no plano gratuito.
- Gere seus assets 3D com o Tripo
