Construye una biblioteca de activos 3D con IA y capacidad de búsqueda usando Tripo y Zilliz
La generación 3D con IA está facilitando enormemente a los equipos la creación de activos 3D a escala. Con Tripo, los creadores pueden generar modelos 3D de alta calidad a partir de prompts de texto o imágenes de referencia, lo que resulta útil para el desarrollo de videojuegos, la visualización de comercio electrónico, la producción de marketing, el diseño de conceptos y los flujos de trabajo creativos internos.
Pero una vez que el número de activos generados crece, surge un nuevo problema.
¿Cómo encontrar rápidamente el activo 3D adecuado?
Cuando un equipo solo tiene unos pocos modelos, los nombres de las carpetas y la navegación manual pueden ser suficientes. Pero una vez que hay cientos o miles de activos generados, el enfoque tradicional de gestión de archivos empieza a fallar. Los diseñadores pueden generar activos similares repetidamente. Los equipos de videojuegos pueden perder el rastro de variaciones útiles de personajes o props. Los equipos de marketing pueden pasar más tiempo buscando activos que utilizándolos.
Ahí es donde cobra valor una biblioteca de activos 3D con IA y capacidad de búsqueda.
En este flujo de trabajo, Tripo genera los activos 3D, mientras que Zilliz Cloud actúa como la capa de recuperación para vectores multimodales y metadatos. Almacena los embeddings que representan cada imagen de renderizado y los conecta con campos útiles como categoría, estilo, color, tipo de objeto, caso de uso y archivo de origen. El resultado es un sistema de recuperación multimodal ligero donde los usuarios pueden buscar con texto, una imagen de referencia o ambos, y obtener imágenes de renderizado generadas por Tripo que coincidan junto con metadatos estructurados.
Zilliz es una empresa de infraestructura de datos de IA y creadora de Milvus, la base de datos vectorial de código abierto detrás de este flujo de trabajo. Milvus está diseñada para casos de uso de IA en producción como RAG, agentes de IA, búsqueda multimodal, sistemas de recomendación, bases de conocimiento empresariales, búsqueda semántica y deduplicación de contenido. También es un proyecto graduado de la Linux Foundation AI & Data con más de 44,000 estrellas en GitHub y más de 100 millones de descargas en Docker, lo que ofrece a los equipos una base familiar para almacenar y recuperar embeddings vectoriales de datos no estructurados.
Esto es importante para los usuarios de Tripo porque cada activo 3D es más que un único archivo. Cada modelo se puede conectar a una vista previa de renderizado, una imagen de referencia de entrada, una descripción, etiquetas, categorías, colores, casos de uso, IDs de proyecto y URLs. Zilliz Cloud hace que estas señales se puedan buscar de forma conjunta, de modo que una biblioteca creciente de modelos generados por IA se convierta en un sistema de activos de producción reutilizable en lugar de una carpeta de resultados de un solo uso.
Por qué construir una biblioteca de activos 3D con capacidad de búsqueda
Las herramientas de 3D con IA son excelentes para la velocidad de producción. Un solo creador ahora puede generar múltiples conceptos de personajes, maquetas de productos, props, elementos de entorno o activos estilizados en muy poco tiempo.
Sin embargo, la velocidad genera volumen. El volumen genera problemas de gestión.
Una biblioteca de activos 3D con capacidad de búsqueda ayuda a resolver varios problemas comunes:
- Los equipos pueden encontrar rápidamente activos existentes en lugar de generar duplicados.
- Los diseñadores pueden buscar por concepto, estilo, color, tipo de objeto o caso de uso.
- Los desarrolladores pueden reutilizar activos 3D en diferentes proyectos de manera más eficiente.
- Los equipos creativos pueden construir una biblioteca interna de materiales visuales aprobados y reutilizables.
- Los equipos de comercio electrónico o marketing pueden organizar activos 3D de tipo producto por categoría y estilo.
En lugar de tratar los archivos 3D generados por IA como salidas de un solo uso, este flujo de trabajo los convierte en un sistema de activos reutilizable.
Por qué Zilliz Cloud se adapta a la búsqueda multimodal de activos 3D
Zilliz Cloud es una plataforma de Vector Lakebase totalmente gestionada y construida por los creadores de Milvus. En su núcleo se encuentra una base de datos vectorial de grado de producción para búsquedas vectoriales de alto rendimiento y baja latencia a escala de 100 mil millones. Alrededor de ese núcleo, Zilliz Cloud amplía la búsqueda vectorial con la apertura, escalabilidad y economía de los data lakes multimodales, ofreciendo a los equipos una única plataforma para buscar, analizar y gobernar datos no estructurados para la IA en producción.
Esto se adapta a una biblioteca de activos de Tripo porque los datos son multimodales por naturaleza. Un catálogo 3D con capacidad de búsqueda puede necesitar trabajar con imágenes de renderizado, imágenes de referencia, descripciones de texto, metadatos generados, campos de propiedad del equipo y etiquetas específicas del proyecto al mismo tiempo. Zilliz Cloud conecta esas señales a través de la búsqueda vectorial y la recuperación de metadatos, de modo que los usuarios puedan encontrar activos por significado, similitud visual, filtros estructurados o una combinación de los tres.
Zilliz explica esta evolución del producto en De base de datos vectorial a Vector Lakebase y Por qué construimos Vector Lakebase. La idea clave es que los sistemas de IA modernos necesitan más que una búsqueda de vecinos más cercanos. También necesitan una base de datos para el servicio en tiempo real, el descubrimiento iterativo, la analítica por lotes y la gobernanza sobre conjuntos de datos no estructurados de rápido crecimiento. Esas necesidades se corresponden directamente con las bibliotecas de 3D con IA, donde los equipos desean recuperar el mejor resultado de hoy y seguir mejorando el catálogo con el tiempo.
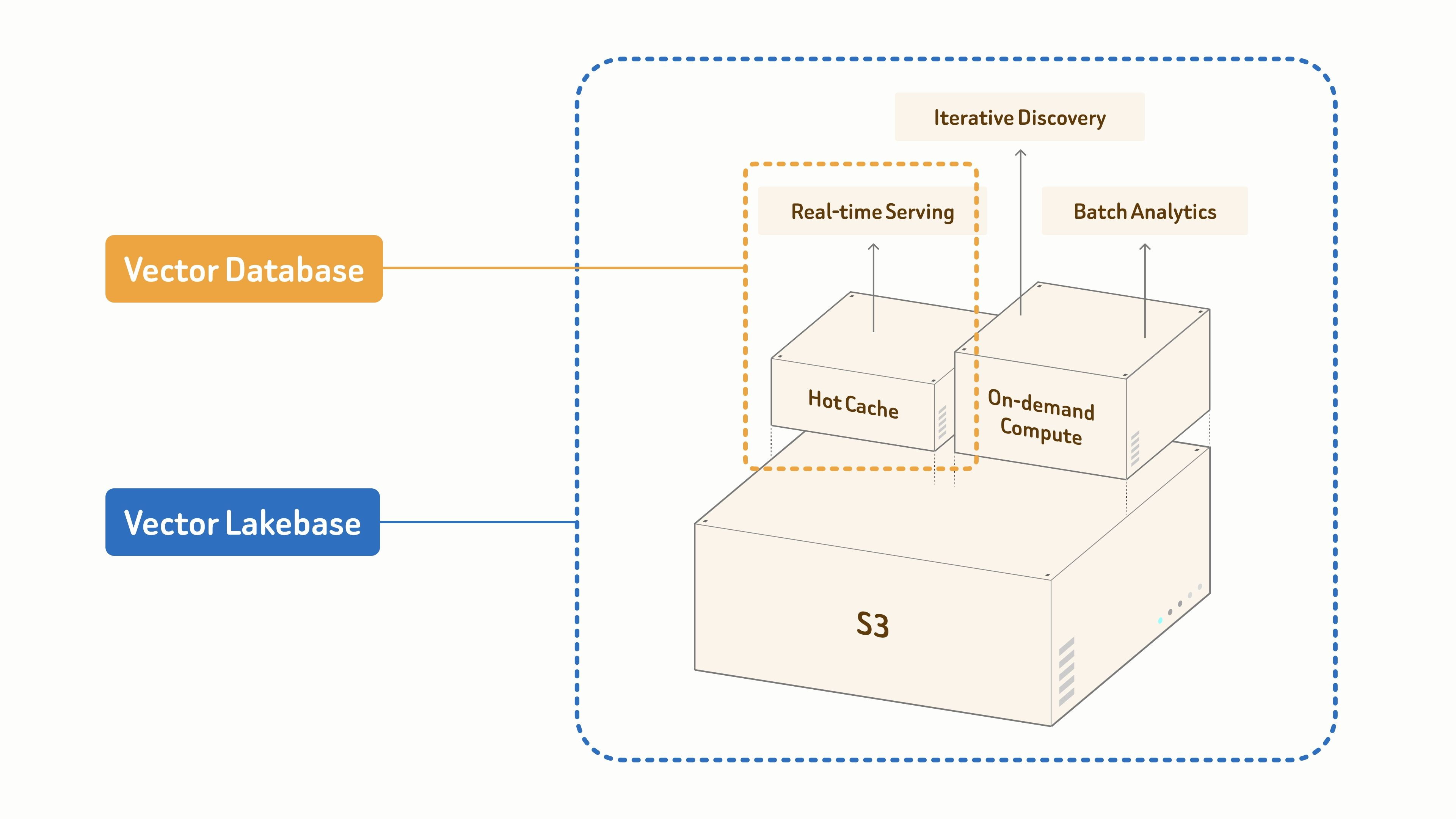
Descripción general del flujo de trabajo
Esta demostración utiliza tres tipos de datos locales:
- El archivo CSV almacena metadatos para cada activo 3D, como categoría, estilo, tipo de objeto, color, caso de uso, nombre de archivo e información del proyecto relacionada.
- La carpeta milvus_render_images/ almacena las imágenes de vista previa renderizadas de los activos generados por Tripo. Estas imágenes de renderizado son los principales objetivos de recuperación.
- La carpeta milvus_input_images/ almacena las imágenes de referencia utilizadas durante la generación de imagen a 3D. Estas se utilizan principalmente como metadatos y como referencias de consulta opcionales.
En términos sencillos: esta configuración permite a los usuarios describir lo que necesitan, subir una referencia visual o combinar ambas entradas para encontrar activos relevantes en la biblioteca.
Requisitos previos
Antes de comenzar, asegúrate de tener lo siguiente:
- Una cuenta de Zilliz Cloud. Zilliz Cloud es una plataforma de Vector Lakebase totalmente gestionada y construida por los creadores de Milvus. Combina una base de datos vectorial de grado de producción con una base nativa de lago para datos multimodales, de modo que puedas almacenar embeddings y metadatos estructurados sin tener que operar la infraestructura vectorial tú mismo. El nivel gratuito es suficiente para seguir este tutorial. Regístrate en Zilliz Cloud, crea un clúster gratuito y obtén su URI y token.
- Una clave de API de OpenRouter para el modelo de embeddings multimodales Gemini utilizado a continuación.
- Python 3.10+ con el SDK de Python de Milvus instalado (
pip install -U pymilvus). Consulta la guía de instalación de PyMilvus si no estás familiarizado con él. - Un conjunto de activos 3D generados por Tripo: imágenes de vista previa de renderizado y, opcionalmente, las imágenes de referencia utilizadas para la generación de imagen a 3D.
Paso 1: Preparar los datos de activos 3D generados por Tripo
El primer paso es preparar los datos generados a través de Tripo.
Cada activo debe tener al menos:
- Una imagen de vista previa de renderizado
- Una fila de metadatos en el CSV
- Información opcional de la imagen de entrada/referencia
- Campos de categoría, estilo, caso de uso, objeto y color cuando estén disponibles
Por ejemplo, un activo podría incluir metadatos como estos:
| Campo | Valor de ejemplo |
|---|---|
| Categoría | Personaje |
| Estilo | Fantasía |
| Tipo de objeto | Guerrera |
| Color | Azul, Plata |
| Caso de uso | Activo de juego |
| Nombre de archivo | warrior_female_01.webp |
Estos metadatos son importantes porque la búsqueda vectorial por sí sola no siempre es suficiente. En una biblioteca de activos real, los usuarios a menudo desean combinar la búsqueda semántica con filtros.
Por ejemplo:
- Buscar un "personaje femenino" en el caso de uso "activo de juego".
- Buscar "espada de fantasía con gema azul" bajo la categoría "arma".
- Buscar activos en un estilo visual específico, como realista, caricatura, ciencia ficción o low poly.
Cuanto mejor sea la estructura de tus metadatos, más útil será tu biblioteca de activos.
Restricción del formato de imagen para embeddings
Las imágenes de renderizado y las imágenes de referencia de entrada se almacenan en formato .webp para optimizar el almacenamiento.
Sin embargo, el modelo de embeddings de Gemini (gemini-embedding-2-preview) solo admite de forma fiable entradas PNG y JPEG. Las imágenes WebP pueden causar fallos en la generación de embeddings dependiendo del backend de la API.
Por lo tanto, se requiere un paso de preprocesamiento para convertir las imágenes a PNG o JPEG antes de generar los embeddings.
Paso 2: Crear una colección en Zilliz Cloud
En Zilliz Cloud, cada registro en la colección representa un activo 3D generado por Tripo.
Aquí es donde el modelo Vector Lakebase resulta útil. Una base de datos vectorial tradicional es excelente para la búsqueda de similitud en tiempo real. Un Vector Lakebase mantiene esa ruta de recuperación al tiempo que añade una base de datos compartida y nativa de lago para datos multimodales, analítica por lotes, descubrimiento iterativo y gobernanza. En esta demostración, lo usamos de forma ligera, pero la misma estructura puede crecer con una biblioteca de activos de Tripo mucho mayor.
La colección almacena tanto metadatos estructurados como un vector multimodal. El campo vectorial clave es multimodal_vector. En esta demostración, la dimensión del vector es 3072 y se utiliza COSINE como métrica de similitud.
Debido a que las consultas de texto, imagen y texto más imagen se integran en el mismo espacio vectorial, el sistema puede buscar en todos los activos utilizando un único campo vectorial unificado.
Aquí tienes la configuración simplificada del esquema:
from pymilvus import MilvusClient
client = MilvusClient(uri=ZILLIZ_URI, token=ZILLIZ_TOKEN)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("asset_id", datatype=DataType.VARCHAR, max_length=64, is_primary=True)
schema.add_field("project_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("operator_id", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("caption", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("llm_category", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_style", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_object_type", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_color", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("llm_use_case", datatype=DataType.VARCHAR, max_length=256)
schema.add_field("generation_mode", datatype=DataType.VARCHAR, max_length=64)
schema.add_field("render_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("input_image_path", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field("multimodal_vector", datatype=DataType.FLOAT_VECTOR, dim=3072)
Luego crea el índice vectorial:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="multimodal_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
Después de definir el esquema y el índice, ejecuta:
client.create_collection(
collection_name="tripo_asset_library",
schema=schema,
index_params=index_params
)
Una vez completado el comando, deberías poder ver la colección en la consola de Zilliz Cloud.
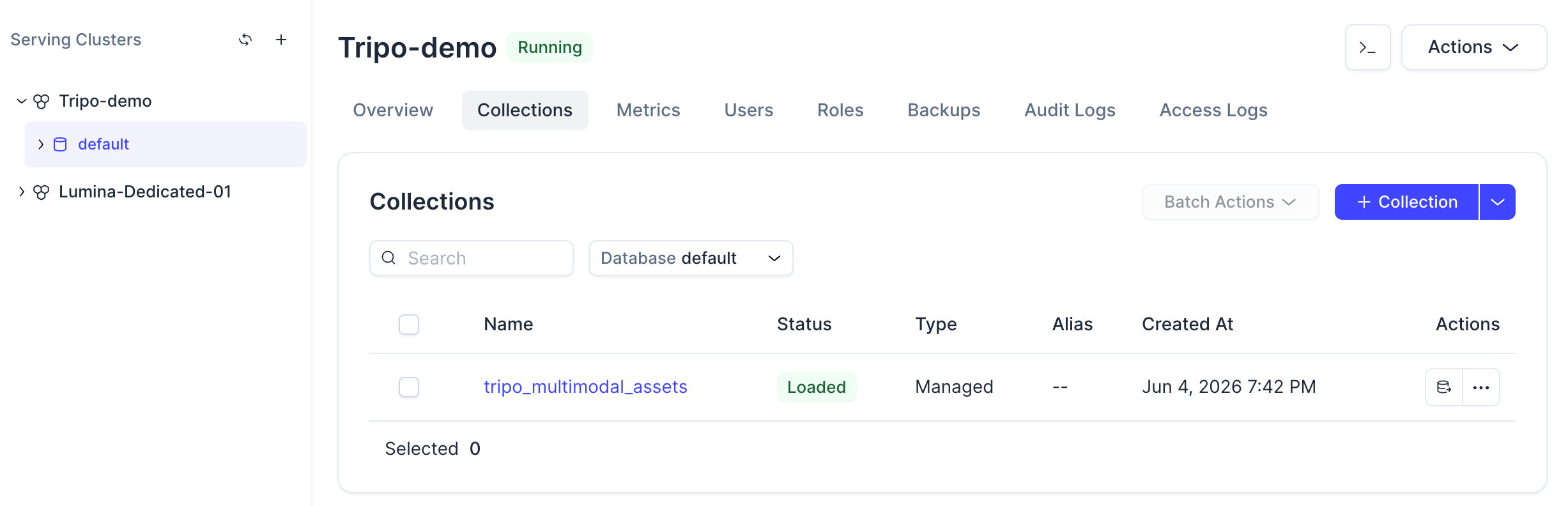
Al hacer clic en la colección, también puedes ver su estado, esquema, entidades cargadas y la configuración del campo vectorial.
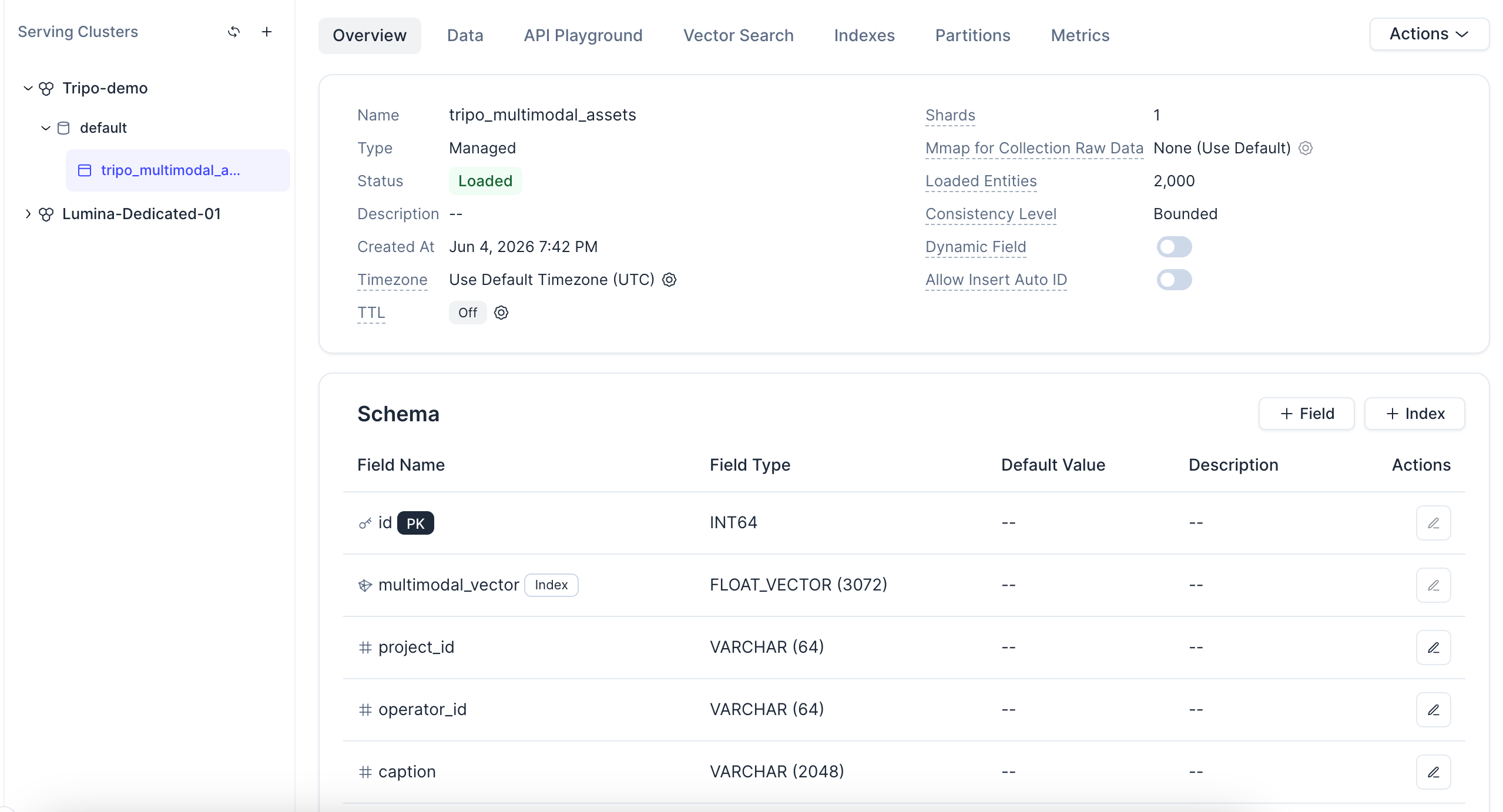
Una nota sobre el índice: esta demostración utiliza AUTOINDEX, lo que permite a Zilliz Cloud elegir y ajustar el índice vectorial por ti en función de tus datos, sin necesidad de seleccionar manualmente los tipos de índice o parámetros. El tipo de métrica COSINE coincide con los embeddings normalizados por L2 generados en el siguiente paso. Y dado que cada registro es una entidad en una colección gestionada, esta misma configuración escala desde cientos de activos hasta millones sin necesidad de rediseñar la arquitectura.
Paso 3: Generar embeddings para las imágenes de renderizado
A continuación, genera embeddings para las imágenes de vista previa de renderizado de Tripo.
En este flujo de trabajo, las imágenes de renderizado se convierten en URLs de datos base64 y se envían a un modelo de embeddings. Los vectores devueltos se normalizan para que puedan usarse con la búsqueda de similitud COSINE.
Aquí está la lógica principal:
import requests
import base64
def get_image_embedding(image_path: str) -> list[float]:
with open(image_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64}"
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={"Authorization": f"Bearer {OPENROUTER_API_KEY}"},
json={
"model": "google/gemini-embedding-2-preview",
"input": [{"data": data_url, "type": "image"}]
}
)
embedding = response.json()["data"][0]["embedding"]
norm = sum(x*x for x in embedding) ** 0.5
return [x / norm for x in embedding]
Para construir la caché de embeddings para el conjunto de datos completo, ejecuta:
import csv, json
embedding_cache = {}
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
render_path = row["render_image_path"]
embedding_cache[render_path] = get_image_embedding(render_path)
with open("embedding_cache.json", "w") as f:
json.dump(embedding_cache, f)
El paso de almacenamiento en caché es útil porque la generación de embeddings puede llevar tiempo y depender de la API. En lugar de generar embeddings cada vez que importas datos, puedes construir la caché una vez y reutilizarla durante el proceso de importación.

Después de generar la caché de embeddings, cada fila del CSV se convierte en una entidad de Zilliz Cloud.
Cada entidad incluye:
- Asset ID
- Project ID
- Operator ID
- Caption
- Metadatos generados por LLM
- Modo de generación
- Información del archivo de imagen de renderizado
- Información del archivo de imagen de entrada
- Vector multimodal
Aquí tienes una versión simplificada de la función de conversión de entidades:
def csv_row_to_entity(row: dict, embedding_cache: dict) -> dict:
render_path = row["render_image_path"]
return {
"asset_id": row["asset_id"],
"project_id": row["project_id"],
"operator_id": row["operator_id"],
"caption": row["caption"],
"llm_category": row.get("category", ""),
"llm_style": row.get("style", ""),
"llm_object_type": row.get("object_type", ""),
"llm_color": row.get("color", ""),
"llm_use_case": row.get("use_case", ""),
"generation_mode": row.get("generation_mode", ""),
"render_image_path": render_path,
"input_image_path": row.get("input_image_path", ""),
"multimodal_vector": embedding_cache.get(render_path, [])
}
Luego, importa el conjunto de datos completo:
entities = []
with open("asset_metadata.csv") as f:
reader = csv.DictReader(f)
for row in reader:
entities.append(csv_row_to_entity(row, embedding_cache))
client.insert(collection_name="tripo_asset_library", data=entities)
Una vez completada la importación, abre la consola de Zilliz Cloud y ve a la pestaña Data. Deberías ver los registros de assets importados, incluyendo los campos de metadatos y la información vectorial.
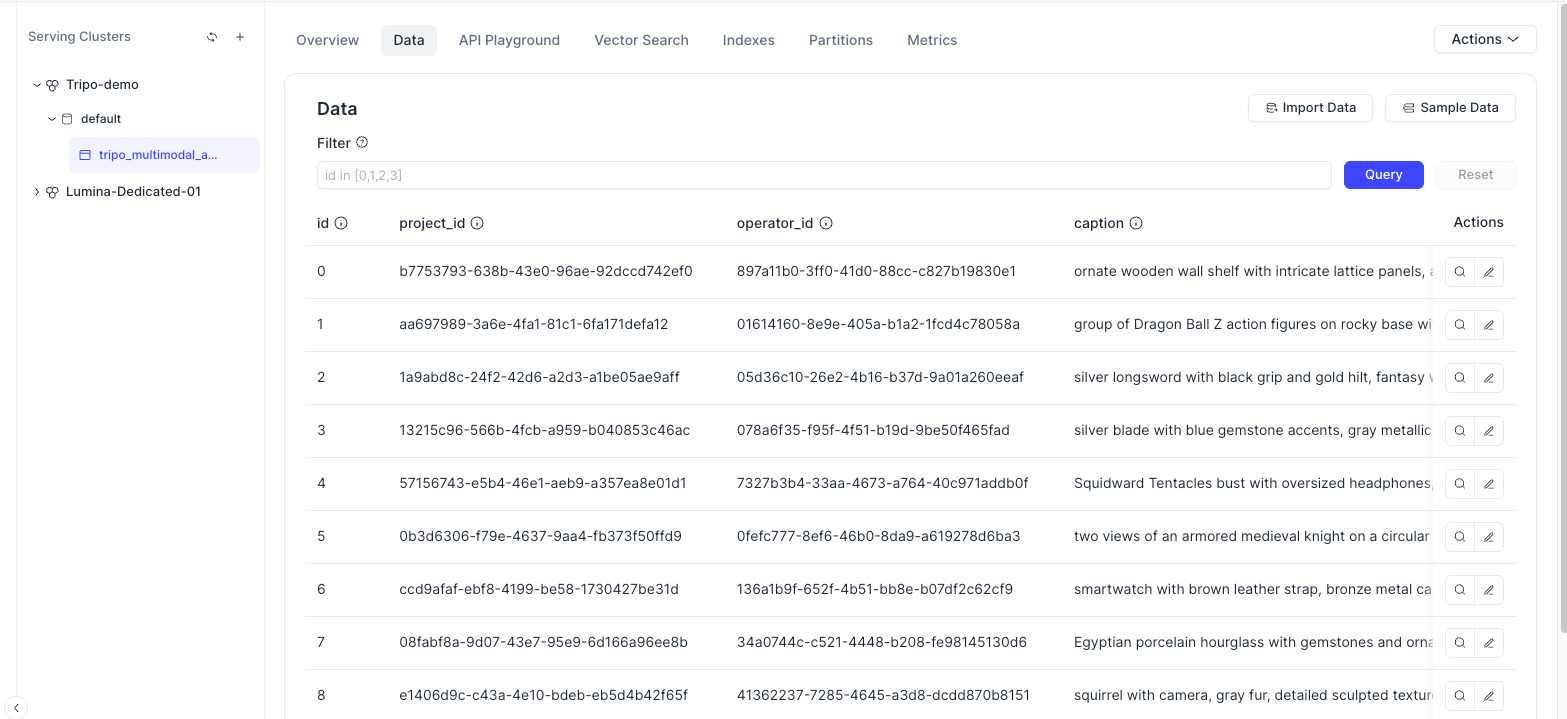
En este punto, los assets 3D generados por Tripo ya no son solo archivos locales. Ahora son entidades con capacidad de búsqueda en una base de datos vectorial.
Paso 5: Buscar en la biblioteca de assets 3D
El sistema de búsqueda admite tres modos de consulta:
- Búsqueda por texto — búsqueda por descripción semántica
- Búsqueda por imagen — búsqueda por similitud visual
- Búsqueda de texto + imagen — combina ambas para una recuperación más precisa
Los tres tipos de consulta se convierten en vectores utilizando el mismo modelo de embedding multimodal. Luego, el vector de consulta se busca en el campo multimodal_vector en Zilliz Cloud.
Búsqueda por texto
La búsqueda por texto es útil cuando el usuario ya sabe lo que quiere.
Ejemplo de consulta: "Un personaje femenino con armadura azul y plateada"
El sistema genera el embedding de la consulta de texto, busca en la colección y devuelve las imágenes de renderizado más cercanas junto con sus metadatos.
Esto es especialmente útil para equipos creativos que desean buscar por intención semántica en lugar de por nombres de archivo exactos. Por ejemplo, un diseñador no necesita recordar si un archivo se llama char_f_warrior_01 o f_warrior_blue. Simplemente puede buscar: "female warrior blue armor". Esa es la diferencia entre un archivo de almacenamiento de archivos y un sistema real de recuperación de assets.
Búsqueda por imagen
La búsqueda por imagen es útil cuando el usuario tiene una imagen de referencia y desea encontrar assets 3D visualmente similares.
Por ejemplo, un artista de videojuegos podría subir una imagen de referencia de un escudo estilizado y buscar props similares generados por Tripo en la biblioteca existente. En lugar de navegar manualmente a través de cientos de imágenes, el sistema puede recuperar assets que coincidan con la estructura visual, el estilo o el concepto del objeto de la referencia subida.
Búsqueda de texto + imagen
La búsqueda de texto más imagen es la opción más flexible. Permite al usuario combinar la intención semántica con una guía visual.
Por ejemplo, el usuario podría subir una imagen de referencia de una espada y agregar una consulta de texto: "espada de fantasía con gema azul". La imagen proporciona la referencia visual, mientras que el texto acota la intención de búsqueda. Esto hace que la recuperación sea más específica que si se utilizara cualquiera de los dos datos por separado.
Aquí tienes la lógica de búsqueda simplificada:
def search_assets(query_embedding: list[float], filter_expr: str = "", limit: int = 12):
return client.search(
collection_name="tripo_asset_library",
data=[query_embedding],
anns_field="multimodal_vector",
filter=filter_expr,
limit=limit,
output_fields=[
"asset_id", "caption", "llm_category",
"llm_style", "llm_use_case", "render_image_path"
]
)
Los resultados devueltos incluyen tanto las puntuaciones de similitud como los metadatos, lo que permite mostrar las vistas previas de los assets coincidentes en una interfaz front-end.
Ten en cuenta que la búsqueda no se limita a la pura similitud vectorial. Como cada asset también contiene metadatos estructurados (categoría, estilo, caso de uso y más), puedes combinar la similitud semántica con condiciones de metadatos en una sola solicitud; por ejemplo, buscar "female" pero restringir los resultados a llm_use_case == "game asset". Esto es la búsqueda filtrada, y es lo que convierte un conjunto de vectores en un catálogo de assets consultable. Si más adelante deseas realizar coincidencias basadas en múltiples señales a la vez, Zilliz Cloud también admite búsquedas híbridas multivectoriales a través de múltiples embeddings por asset.
Ejemplo 1: Búsqueda por texto y caso de uso
En la demostración, un ejemplo de consulta utiliza el texto "female" con el filtro de caso de uso llm_use_case == "game asset" y establece limit=12.
Esto recupera los 12 assets coincidentes más relevantes que están semánticamente relacionados con "female" y pertenecen al caso de uso de asset de videojuego.
Este tipo de búsqueda es útil para los pipelines de desarrollo de videojuegos donde los equipos necesitan localizar rápidamente conceptos de personajes, diseños de NPC, avatares estilizados o assets humanoides en una gran biblioteca interna.
Ejemplo 2: Búsqueda por texto e imagen de referencia
Otro ejemplo combina una consulta de texto con una imagen de referencia.
La consulta de texto es: "Fantasy style weapon with detailed ornamentation and glowing effects". La consulta también incluye una imagen de referencia visual. Luego, el sistema genera un embedding conjunto para el texto y la imagen, busca en el mismo campo vectorial y devuelve las imágenes de renderizado más relevantes.
Esto es útil cuando la intención del usuario es demasiado específica para describirla solo con texto. Para la búsqueda de assets visuales, "similar a esto, pero más parecido a aquello" suele ser exactamente la forma de pensar de los creadores.
Por qué es importante este flujo de trabajo
El valor real aquí no es solo la búsqueda de imágenes, sino una infraestructura reutilizable de assets 3D de IA. Tripo se encarga de la generación rápida; Zilliz Cloud se encarga del almacenamiento de vectores, la búsqueda de similitud, la recuperación de metadatos y la capa de datos detrás de la búsqueda multimodal. Juntos, convierten los resultados 3D aislados en una biblioteca organizada, consultable y reutilizable, lo que mejora directamente la eficiencia de producción para los equipos que crean contenido 3D a escala.
Debido a que Zilliz Cloud está diseñado para IA en producción, este mismo patrón puede comenzar desde algo pequeño y escalar junto con el equipo. Los estudios de videojuegos pueden localizar variaciones de personajes, props y entornos; los equipos de comercio electrónico pueden organizar modelos de productos por categoría, color o material; los equipos de marketing pueden reutilizar elementos visuales existentes en lugar de volver a generarlos; y los equipos de operaciones creativas (creative-ops) pueden mantener un almacén central y consultable de assets aprobados para todos los proyectos.
Conclusión
La generación 3D con IA ahora es lo suficientemente rápida como para que la creación ya no sea el único cuello de botella. El siguiente desafío es qué sucede después de generar un modelo: cómo se almacena, cómo se vuelve a encontrar, cómo se gestiona y cómo se reutiliza en lugar de desaparecer en una carpeta.
Este flujo de trabajo conecta Tripo y Zilliz Cloud para resolver exactamente eso: Tripo genera assets de alta calidad a partir de texto o imágenes de referencia, y Zilliz Cloud añade la capa de recuperación: imágenes de renderizado, embeddings multimodales, metadatos estructurados y búsqueda vectorial escalable. En otras palabras, Tripo se convierte en el motor de creación 3D, mientras que Zilliz Cloud se convierte en la infraestructura de datos de IA que mantiene esas creaciones consultables, reutilizables y listas para el próximo proyecto.
Pruébalo tú mismo
La generación 3D con IA es solo el primer paso; el verdadero beneficio proviene de convertir los assets generados en un sistema estructurado y consultable que escale a través de equipos y proyectos. Con Tripo, generas assets 3D de alta calidad a partir de prompts de texto o imágenes de referencia. Con Zilliz Cloud, los organizas y recuperas mediante búsqueda vectorial multimodal en texto e imágenes, respaldado por una Vector Lakebase gestionada y diseñada para flujos de trabajo de IA en producción.
- Regístrate en Zilliz Cloud y sigue este tutorial de principio a fin en el nivel gratuito.
- Genera tus assets 3D con Tripo
